“Tildes” mākslīgais intelekts iezīmē jaunu ēru tulkošanā starp Eiropas valodām
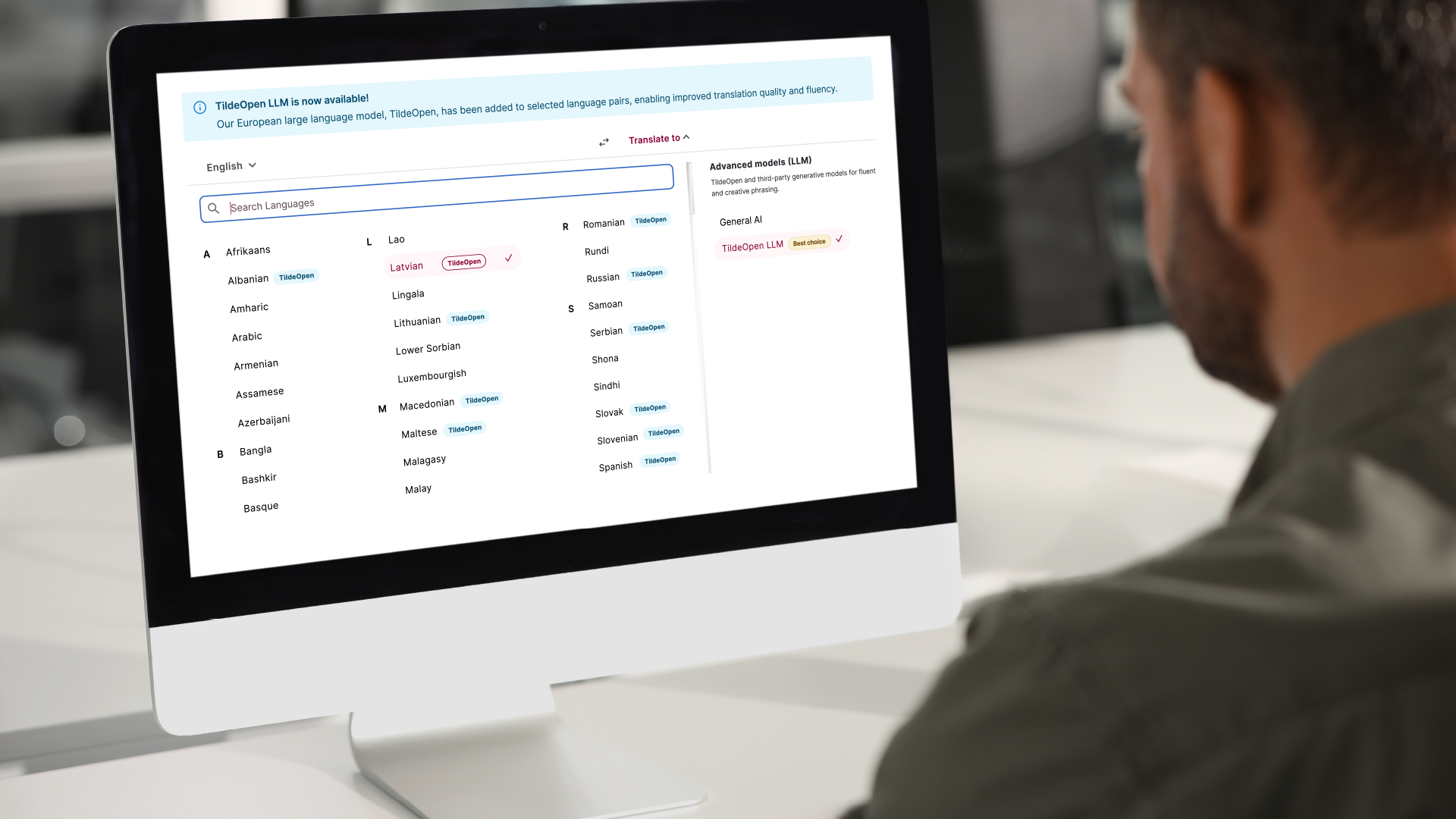
Latvijas valodu tehnoloģiju uzņēmums “Tilde” ir pielāgojis savu lielo valodas modeli TildeOpen LLM tulkošanai un integrējis to mašīntulkošanas platformā, kas nodrošinās kvalitatīvus un uzticamus tulkojumus 34 Eiropas valodām. Līdz šim modelis galvenokārt bija nozīmīgs zinātnisks sasniegums Eiropas valodu mākslīgā intelekta attīstībā, taču vēl nebija pielāgots ikdienas lietošanai plašākai auditorijai. Tagad tas ir publiski pieejams lietotājiem gan privātām tulkošanas vajadzībām, gan ikdienas darbam.
Ikviens var izmantot tulkošanas platformu, kas nodrošina īpaši kvalitatīvu un drošu tulkošanu 34 Eiropas valodās, tostarp arī latviešu, lietuviešu un igauņu, un paredz akurātu terminoloģijas lietojumu un dabiskākus, plūstošus teikumus, samazinot nepieciešamību mašīntulkotos tekstus labot.i.
TildeOpen kvalitātes ziņā spēj konkurēt ar daudz lielākiem globāliem modeļiem, piemēram, ChatGPT-4.1, lai gan ir aptuveni 60 reižu mazāks. Detalizēti salīdzinošo testu rezultāti ir pieejami lielo valodas modeļu ranžējumā TildeBench.
Organizācijas var izvietot TildeOpen savā infrastruktūrā vai Eiropas mākoņos, tādējādi saglabājot pilnīgu kontroli pār saviem datiem. Atšķirībā no daudziem globālajiem mākslīgā intelekta risinājumiem dati netiek nodoti ārpus Eiropas. Tas ir īpaši svarīgi valsts iestādēm un uzņēmumiem, kas strādā ar sensitīvu informāciju. Vienlaikus pastāv iespēja pielāgot modeli konkrētām vajadzībām, tādējādi nodrošinot īpaši precīzus un uzticamus tulkojumus.
“TildeOpen integrācija mašīntulkošanā ir nozīmīgs solis Eiropas valodu mākslīgā intelekta praktiskā lietošanā. Mūsu mērķis ir nodrošināt, lai augstas kvalitātes valodu tehnoloģijas būtu ne tikai pieejamas, bet arī uzticamas ikdienas darbā,” norāda “Tildes” vadītājs Artūrs Vasiļevskis.
Tildeopen tika publicēts kā atvērtā pirmkoda pamatmodelis Eiropas valodām Hugging Face platforma 2025. gada rudenī. Tā tika izstrādāta Tildes pētniecības laboratorijā Eiropas Komisijas vārdā. Modelim ir 30 miljardi parametru, un tas ir apmācīts simtiem miljardu vārdu Eiropas valodās, tostarp 29 miljardi latviešu teksta vienību. Tas ir lielākais zināmais datu apjoms, ko izmanto Latvijas mākslīgā intelekta attīstībā. Modelis tika izstrādāts pēc uzvaras lielajā AI Grand Challenge konkursā, ko organizēja Eiropas Komisija, izmantojot LUMI superdatoru Somijā.
Vai vēlaties ieviest MI arī savā organizācijā?
Sazinieties ar mums jau šodien un noskaidrojiet, kā mūsu risinājumi var uzlabot jūsu darbplūsmu.