Tildeopen LLM: Europos suvereni daugiakalbė AI
Atviras, pamatinis LLM (didelės kalbos modelis) Europos kalboms – saugus, pritaikomas ir parengtas vyriausybėms, institucijoms ir įmonėms.
2024 m. birželio mėn.
„Tilde“ laimi didelius ai didžiuosius iššūkius
2024 m. rugsėjis
Prieiga prie LUMI
gautas superkompiuteris
2025 m. kovo mėn.
Modelio mokymas
prasideda
2025 m. rugsėjis
Modelis gyvas apkabinant veidą
2026 m. vasario mėn.
TildeOpen pradėjo veikti
Tilde MT

Jūsų kalba nusipelno geresnio DI
Dauguma DI modelių sukurti pagrindinėms pasaulio kalboms ir daugiau kaip 90 % LLM mokymo duomenų yra anglų kalba. Tai reiškia, kad Baltijos šalių, slavų ir kitos Europos kalbos yra paliktos nuošalyje, todėl sumažėja tikslumas, prastėja supratimas apie kultūrą, o prieiga prie aukštos kokybės DI priemonių yra ribota.
Todėl sukūrėme „TildeOpen LLM“ – atviro kodo pamatinį didelės kalbos modelį su daugiau nei 30 mlrd. parametrų, sukurtą visoms Europos kalboms palaikyti. Galite jį pritaikyti savo poreikiams ir saugiai įdiegti – vietoje arba debesyje – kad sukurtumėte patikimą AI, kuri iš tikrųjų kalba jūsų kalba.

Kodėl TildeOpen?
- Galima tinkinti naudojant savo duomenis
- Saugu ir visiškai valdoma
- Diegiama vietoje arba debesyje
- Integruojama su esamomis sistemomis ir darbo eigomis
- Skirta naudoti kaip pagrindas pažangiems DI sprendimams

DI pagrindas, kuriuo galite pasitikėti
Tildeopen yra daugiau nei technologinis laimėjimas. Tai atviras paprotinės AI pagrindas, naudingas daugiau kaip 155 mln. europiečių.
Individualūs AI sprendimai įmonėms ir organizacijoms
Pritaikykite TildeOpen savo pramonei, duomenims ir darbo eigoms – nuo virtualiųjų asistentų iki saugaus vertimo, kalbėjimo technologijų ir kt.
Nacionalinių kalbų modelių kūrimas vyriausybėms
Kurkite įtraukiuosius kalbų modelius, kurie tenkina visuomenės poreikius, skatina skaitmeninį suverenumą ir palaiko visas oficialias ES kalbas.
Patikimas efektyvumas visose tikslinėse kalbose
Tildeopen nuosekliai rodo didelį kalbinį tikslumą ir supratimą viešuosiuose lyginamuosiuose standartuose
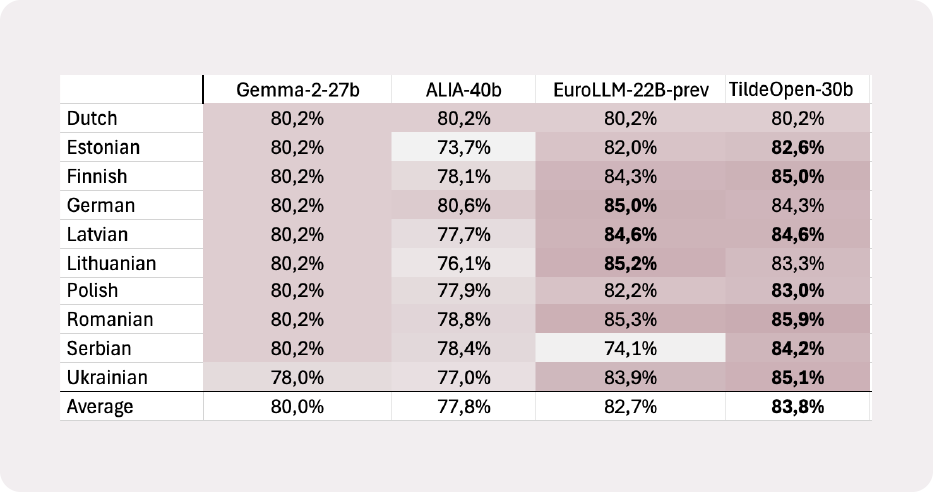
Tildeopen aktyviai veikia Multiblimp lyginamasis standartas, pagal kurį vertinamas modelio gebėjimas atskirti gramatinius ir negramatinius sakinius. Mažesni klaidų lygiai atspindi stipresnį gramatikos modeliavimą ir patikimesnį teksto generavimą. Peržiūrėti visus sąlyginio etalono rezultatus.
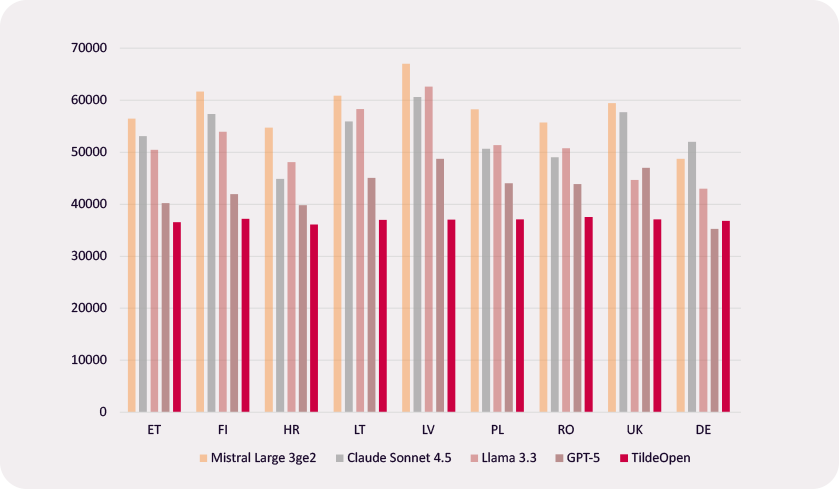
Dėl specialiai jiems sukurto tokenizatoriaus ir architektūros tildeopen daug morfologijos turtingų Europos kalbų vartojimo efektyvumas yra didesnis. Palyginti su Lama-3, jis yra 41% veiksmingesnis latvių kalba, 37% – lietuvių kalba, 31% inFinnish, 28 – estų% ir lenkų kalbomis, taip pat viršija GPT ir Mistral modelius. Tai lemia greitesnį teksto generavimą vietiniuose diegimuose ir atitinkamai mažesnes to paties kiekio duomenų eksploatavimo išlaidas. Peržiūrėti visus sąlyginio etalono rezultatus.
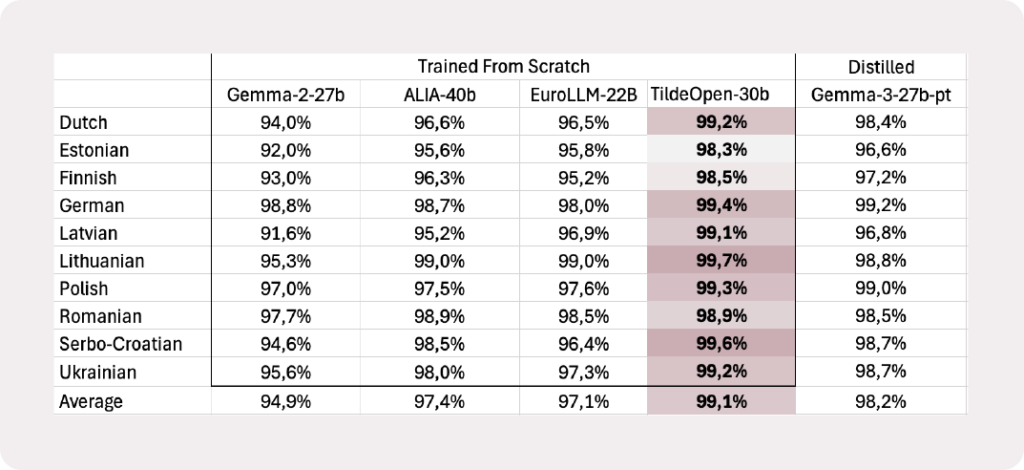
Tildeopen-30B pasiekia naujausią Belebele skaitymo supratimo kriterijaus rezultatą, kurio vidutinis tikslumas yra 84,7%. Šis modelis yra pranašesnis už kitus vietoje diegiamus modelius, pvz., Gemma-27B, ALIA-40B ir EuroLLM-22B. Peržiūrėti visus sąlyginio etalono rezultatus.
Pagrįsta superkompiuteriais, kuriuos palaiko Europa
TildeOpen plėtrą remia Europos Komisija ir BĮ „EuroHPC“ aukščiausios klasės superkompiuteriais: LUMI ir „Jupiter“. Laimėjus „Large AI Grand Challenge“, mums LUMI buvo skirta 2 milijonai GPU valandų šiam ambicingam projektui įgyvendinti.

Indėlis į daugiakalbę ateitį

Pradėkite apkabindami veidą
Apkabinkite veidą, kad ištyrinėtumėte TildeOpen-30b saugyklą ir pasiektumėte visą techninę dokumentaciją.






Mūsų pažadas
Įsipareigojimas neriboti bendradarbiavimo
Vyriausybės gali pasitelkti TildeOpen, kad sukurtų specialiai pritaikytus kalbų modelius, kurie pagerintų viešųjų paslaugų prieinamumą visiems piliečiams.
Vientisumas ir sauga
Nuolat stengiamės sumažinti žalingą arba netikslų TildeOpen turinį, kad jis galėtų būti patikimas įvairių viešojo naudojimo atvejų šaltinis.
Atvira prieiga
Tildeopen bus galima naudoti tiek komerciniais, tiek nekomerciniais tikslais pagal licencinę sutartį, paskelbtą „apgaule face“ ir „ELRC-SHARE“.
Dalijimasis žiniomis
Esame įsipareigoję bendradarbiauti ir dalytis įžvalgomis, kviečiame partnerius dirbti su mumis tobulinant TildeOpen visų labui.
Dažnai užduodami klausimai
Kas yra TildeOpen LLM?
Kuo svarbi LLM kalbų lygybė?
Kokioms kalboms skirtas TildeOpen projektas?
Kas yra superkompiuteris LUMI?
Kas yra „Large AI Grand Challenge“?
Kas yra „Tilde“?
„Tilde“ yra pirmaujanti Europos kalbų technologijų novatorė ir paslaugų teikėja, kurios užduotis – skatinti kalbų įvairovę skaitmeniniame amžiuje. Tilde dirba daugiau kaip 150 darbuotojų trijuose biuruose Rygoje, Vilniuje ir Taline. „Tilde“ mokslinių tyrimų grupę sudaro devyni daktarai ir jų mokslinių tyrimų partneriai, kurie yra sukūrę daugiau kaip 260 mokslinių leidinių. Per daugelį metų Tilde sukūrė platų MTTP partnerystės tinklą su pagrindiniais ES mokslinių tyrimų centrais ir universitetais ir yra Baltijos regiono kalbos technologijų mokslinių tyrimų centras.
Naujausia „Tilde“ mokslinių tyrimų ir technologinės plėtros veikla daugiausia susijusi su pamatiniais didžiaisiais kalbos modeliais (LLMs), galutinės grandies taikomųjų programų LLM tobulinimu ir pagal instrukcijas pritaikytų LLM integravimu į natūralios kalbos apdorojimo taikomąsias programas. (pvz., mašininis vertimas, virtualūs padėjėjai, paieškos išplėstinės generavimo sistemos, šnekamosios kalbos apdorojimas, apibendrinimas ir t. t.).