An open-source, foundational LLM (Large Language Model) for European languages – secure, adaptable, and ready for governments, institutions, and enterprises.
Most AI models are built for the world’s major languages – and over 90% of LLM training data is in English. That means Baltic, Slavic, and other European languages are left behind, leading to lower accuracy, weaker cultural understanding, and limited access to high-quality AI tools.
That’s why we’ve developed TildeOpen LLM – an open-source foundational large language model with over 30 billion parameters, built to support all European languages. You can fine-tune it to your own needs and deploy it securely – locally or in the cloud – to build trustworthy AI that actually speaks your language.
TildeOpen is more than a technological achievement. It’s an open-source foundation for custom AI, benefiting over 155 million Europeans.
Custom AI solutions for businesses and organisations
Adapt TildeOpen to your industry, data, and workflows — from virtual assistants to secure translation, speech tech, and more.
National language model development for governments
Build inclusive language models that serve public needs, promote digital sovereignty, and support all official EU languages.
Reliable performance across focus languages
TildeOpen consistently demonstrates strong linguistic accuracy and comprehension in public benchmarks
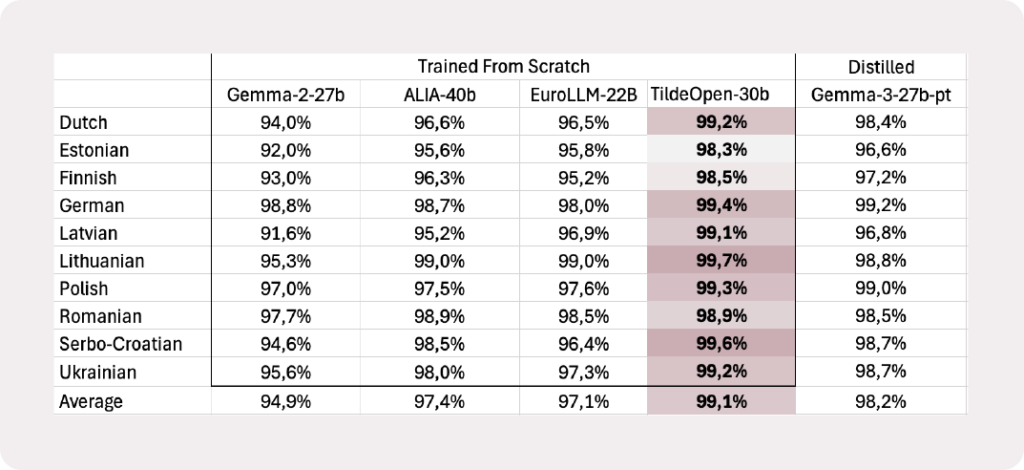
TildeOpen performs strongly on the MultiBLiMP benchmark, which measures a model’s ability to distinguish between grammatical and ungrammatical sentences. Lower error rates reflect stronger grammar modelling and more reliable text generation. View full benchmark results.
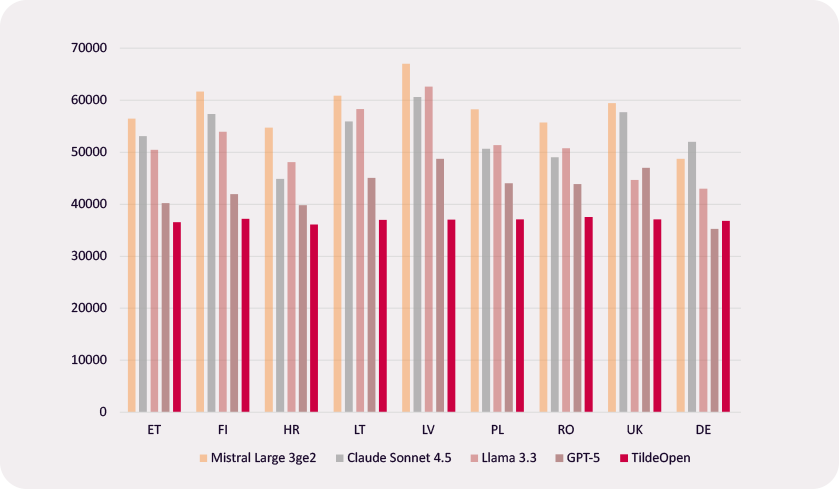
TildeOpen delivers higher efficiency in morphology-rich European languages thanks to a tokeniser and architecture designed specifically for them. Compared to LLaMA-3, it is 41% more efficient in Latvian, 37% in Lithuanian, 31% inFinnish, and 28% in Estonian and Polish, while also surpassing GPT and Mistral models. This translates to faster text generation performance in local deployments and consequently lower running costs for the same amount of data. View full benchmark results.
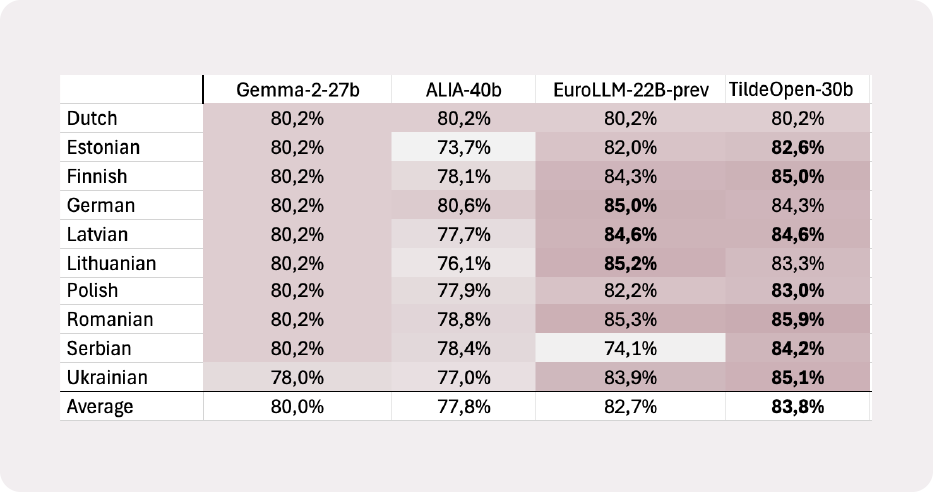
TildeOpen-30B achieves a state-of-the-art result on the Belebele reading comprehension benchmark, with an average accuracy of 84.7%. The model outperforms other locally deployable models such as Gemma-27B, ALIA-40B and EuroLLM-22B. View full benchmark results.
Powered by supercomputers, backed by Europe
The development of TildeOpen is supported by the European Commission and powered by EuroHPC JU’s top-tier supercomputers – LUMI and Jupiter. By winning the Large AI Grand Challenge, we’ve been granted 2 million GPU hours on LUMI to execute this ambitious project.
Contribute to a multilingual future
To build a strong multilingual LLM with over 30B parametrs, we’re looking for language data from across Europe. We welcome contributions from authors, publishers, state libraries, and other partners – with flexible terms that work for you.
Data providers that have already contributed to the project:
Our promise
Committing to open collaboration
Governments can leverage TildeOpen to create tailored language models that improve public service accessibility for all citizens.
Integrity and security
We’re continuously working towards minimising harmful or inaccurate content in TildeOpen, so it can be a trusted resource for diverse public use cases.
Open access
TildeOpen will be available for both commercial and non-commercial use under a permissive license, published in Hugging Face and ELRC-SHARE.
Knowledge sharing
We are committed to collaboration and sharing insights, inviting partners to work with us in advancing TildeOpen for the benefit of all.
Frequently asked questions
What is TildeOpen LLM?
The TildeLM project aims to create a multilingual foundational large language model that focuses on underrepresented Baltic and Eastern European languages to promote digital equity and enhance access to advanced AI technologies for these communities.
Why is language equity in LLMs important?
This imbalance has efficiency and cost consequences. For instance, longer sequences are required to encode the same amount of information in lower-resourced languages compared to English, making models less efficient and more expensive to run. Additionally, the English-centricity of these models can introduce undesirable cultural biases. TildeLM will be trained to ensure equity for all supported languages.
What languages does the TildeOpen project focus on?
The project targets Eastern European and Baltic languages such as Bulgarian, Croatian, Czech, Estonian, Finnish, Latvian, Lithuanian, Macedonian, Montenegrin, Polish, Serbian, Slovak, Slovene, and Ukrainian. The model will also support bigger languages such as English, French, German and Russian in balanced proportions to support translation and related multilingual tasks.
What is the LUMI supercomputer?
The LUMI (Large Unified Modern Infrastructure) supercomputer is the fifth fastest supercomputer globally and the fastest in Europe. It is part of the EuroHPC Joint Undertaking, a collaborative effort involving the European Union and European countries to create a world-class high-performance computing (HPC) ecosystem in Europe. The LUMI supercomputer is located in Kajaani, Finland.
What is the Large AI Grand Challenge?
The purpose of the Large AI Grand Challenge, funded by the European Commission, is to expand European AI frontiers by harnessing the potential of large-scale AI models. The participants in the competition were innovative startups and SMEs with the technical capacity to develop AI models that boost Europe’s competitiveness in Generative AI.
The European Commission has announced the winners of the Large AI Grand Challenge. Four innovative AI companies from Europe, including Tilde, will share a prize of €1 million and 8 million computational hours to advance Europe’s leadership in AI development.
What is Tilde?
Tilde is a leading European language technology innovator and service provider with a mission to promote language diversity in the digital age. Tilde has over 150 employees in three offices located in Riga, Vilnius, and Tallinn. Tilde’s research team is comprised of nine PhDs and their research associates and has authored over 260 scientific publications. Over the years, Tilde has developed a vast R&D partnership network with leading EU research centres and universities and serves as a language technology research hub for the Baltic region.
Most recent research and development activities of Tilde are focused on foundational large language models (LLMs), fine-tuning of LLMs for downstream applications, and integration of instruction-tuned LLMs in natural language processing applications (e.g., machine translation, virtual assistants, retrieval-augmented generation systems, processing of spoken language, summarisation, etc.).
Build AI that speaks your language
TildeOpen gives you the foundation to create secure and sovereign AI. Explore the model now or talk to us about tailoring it to your needs.