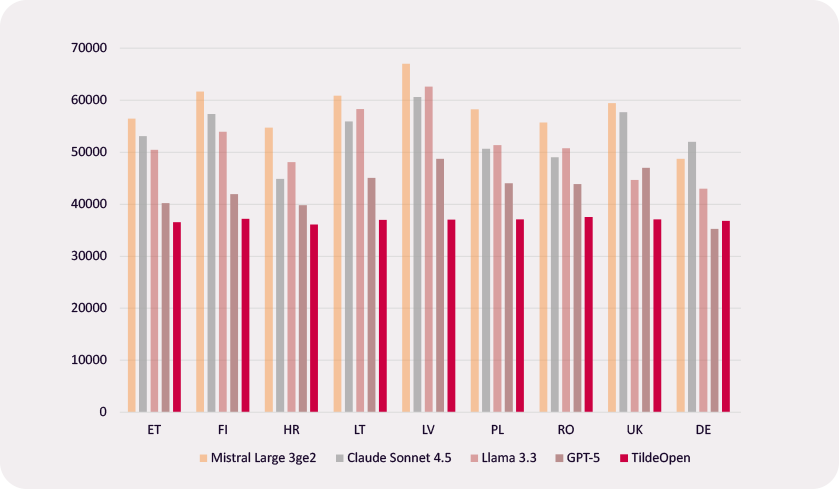
TildeOpen nodrošina augstāku efektivitāti morfoloģiski bagātās Eiropas valodās, pateicoties īpaši tām pielāgotam tokenizatoram un arhitektūrai. Salīdzinot ar LLaMA-3, tas ir par 41% efektīvāks latviešu valodā, par 37% lietuviešu valodā, par 31% somu valodā un par 28% igauņu un poļu valodā, vienlaikus pārspējot arī GPT un Mistral modeļus. Tas nodrošina ātrāku teksta ģenerēšanu lokālas izvietošanas gadījumos un tādējādi zemākas ekspluatācijas izmaksas par to pašu datu apjomu. Apskatiet pilnus testa rezultātus šeit..
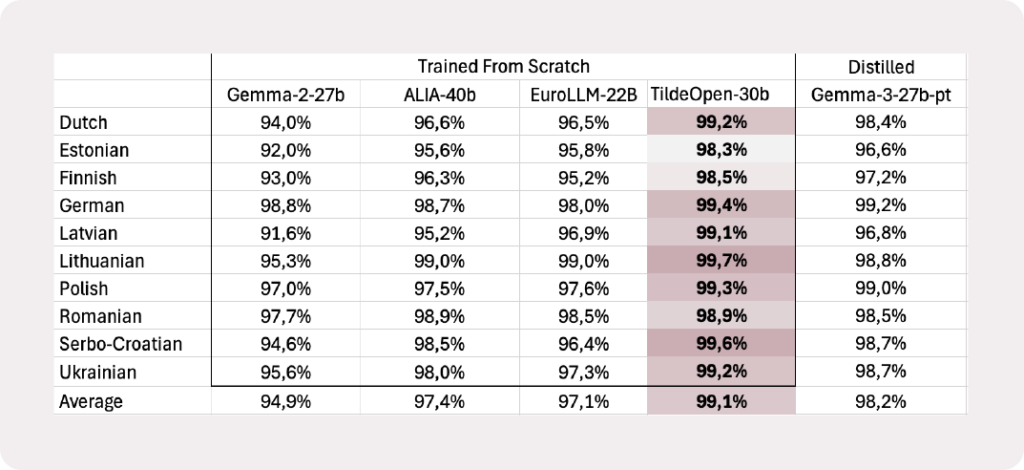
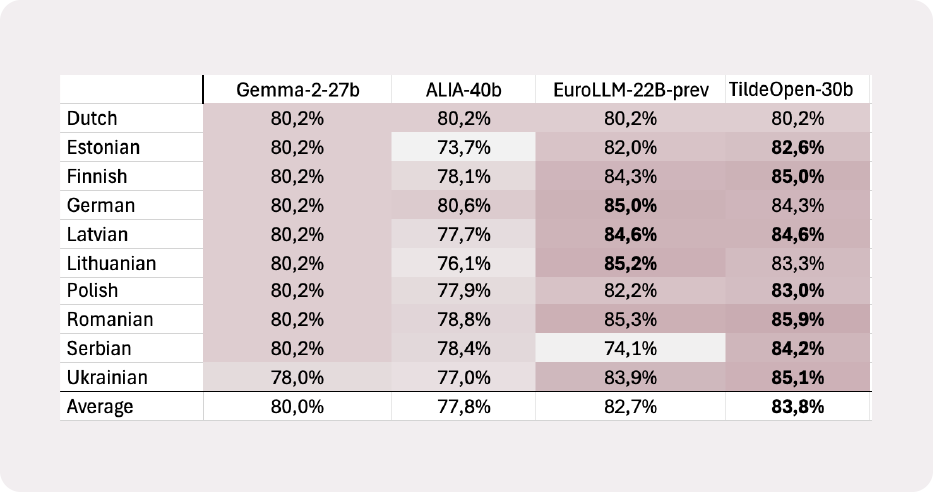
TildeOpen-30B sasniedz nozares līmeņa labāko rezultātu Belebele lasīšanas izpratnes testā, sasniedzot vidējo precizitāti 84,7%. Modelis pārspēj citus lokāli izvietojamus modeļus, piemēram, Gemma-27B, ALIA-40B un EuroLLM-22B. Apskatiet pilnus testa rezultātus šeit..