
Dr. Toms Bergmanis, MI pētnieks Tildē
Lai izveidotu mākslīgā intelekta (MI) sistēmas, kas spēj saprast un ģenerēt cilvēka valodu, ir nepieciešams milzīgs daudzums valodas datu. Šie dati veido pamatu lielo valodas modeļu (LVM) spējai izprast rakstīto un radīt tekstu, kurš līdzinās cilvēka teiktajam. Taču šeit ir vietā atgādināt klišeju, ka ne visi dati ir vienlīdz labi. Šis nošķīrums var būt izšķirošs modeļa kvalitātei.
Spriežot pēc neseno Eiropas un Amerikas LVM metadatu kartītēm, var rasties iespaids, ka LVM apmācībai ir pieejams milzīgs teksta apjoms. Tomēr realitātē tikai daļa no tā ir kvalitatīvi cilvēka izraudzīti dati, kamēr lielākā daļa iegūta, oportūniski vācot datus no tīmekļa.
Tildei izstrādājot daudzvalodu pamata LVM (foundational LLM) ar nosaukumu TildeLM, pazīstamā mantra “atkritumi iekšā, atkritumi ārā” (garbage in, garbage out) rada praktisku problēmu. No vienas puses, mēs lēšam, ka 30 miljardu parametru pamata LVM apmācīšanai ir vajadzīga aptuveni 600–700 miljardu vārdu liela datu kopa. No otras puses, tiklīdz sākam pētīt pieejamo datu kvalitāti, tas, kas pirms brīža izskatījās pēc dārgumu krātuves, sāk izskatīties drīzāk pēc Pandoras lādes.
Pašreizējo datu kopu nepilnības
Vairums LVM apmācībai pieejamo datu tiek iegūti no diviem galvenajiem avotiem: Common Crawl un Internet Archive. Tie ir repozitoriji, kas izveidoti, vācot saturu no miljoniem tīmekļa lapu. Lai gan šie avoti nodrošina bagātīgu datu materiālu, tiem piemīt arī būtiski trūkumi, jo īpaši, ja teksts nav angļu valodā.
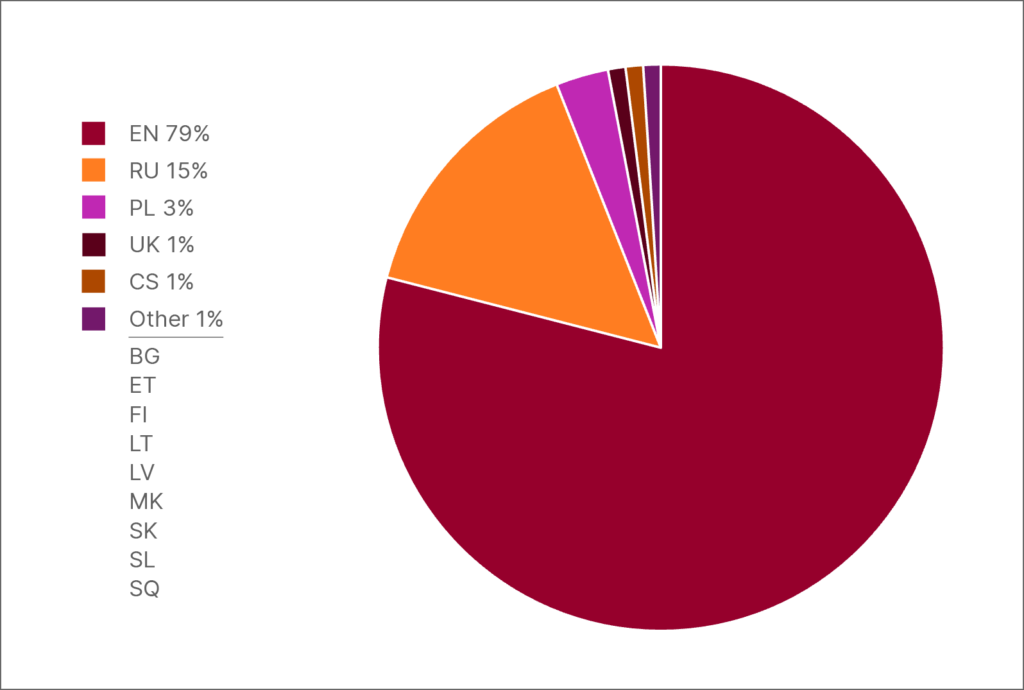
Datu sadalījums versijā HPLT-v2: angļu valoda, salīdzinot ar 13 valodām, kurās runā vairāk nekā 250 miljoni cilvēku
Neatkarīgi no datu kopas izcelsmes visizplatītākā valoda ir angļu: visās datu kopās angļu valodas vārdu skaits ir iespaidīgā pārsvarā, tādējādi liekot izskatīties niecīgai ne tikai jebkurai citai atsevišķai valodai, bet pārsniedzot pat vesela reģiona valodu kopējo vārdu skaitu. Tas ir galvenais iemesls, kāpēc pašlaik lielākajā daļā LVM vairāk nekā 90% apmācības datu ir angļu valodā, atstājot daudzas valodas nepietiekami pārstāvētas. Krasais disbalanss nostiprina angļu valodas privileģēto stāvokli: MI modeļi labi apgūst angļu valodu, bet nespēj uztvert citu valodu nianses un kultūras sarežģītību. Nepietiekami pārstāvēto valodu lietotājiem tas nozīmē zemākas kvalitātes MI rīkus un ierobežotu piekļuvi jaunākajām tehnoloģijām.
Bez tam ievērojama daļa teksta, kas nav angļu valodā, ir nekvalitatīvs mašīntulkots saturs. Piemēram, izpētot HPLT-v2 datu latviešu sadaļas 300 visbiežāk lietotos augšējā līmeņa tīmekļa domēnus, konstatējām, ka 25% satura nāk no lielām mašīntulkotām tīmekļa lapām.
Problēmu rada ne tikai tulkojumu zemā kvalitāte, bet arī apstāklis, ka kopumā tulkojumi reti ir uzskatāmi par pietiekami atbilstošu valodas atspoguļojumu, jo pārāk bieži lieto tiešus pārcēlumus no avotvalodas. Šādas burtiskas un neveiklas tulkošanas efektu angliski dēvē par translationese un ietekmē rodas nedabiskas frāzes, gramatikas kļūdas un zūd kultūras konteksts. Līdz ar to MI modeļi, kas apmācīti, izmantojot šādus datus, nespēj efektīvi izprast konkrēto tekstu vai ģenerēt niansētu saturu.
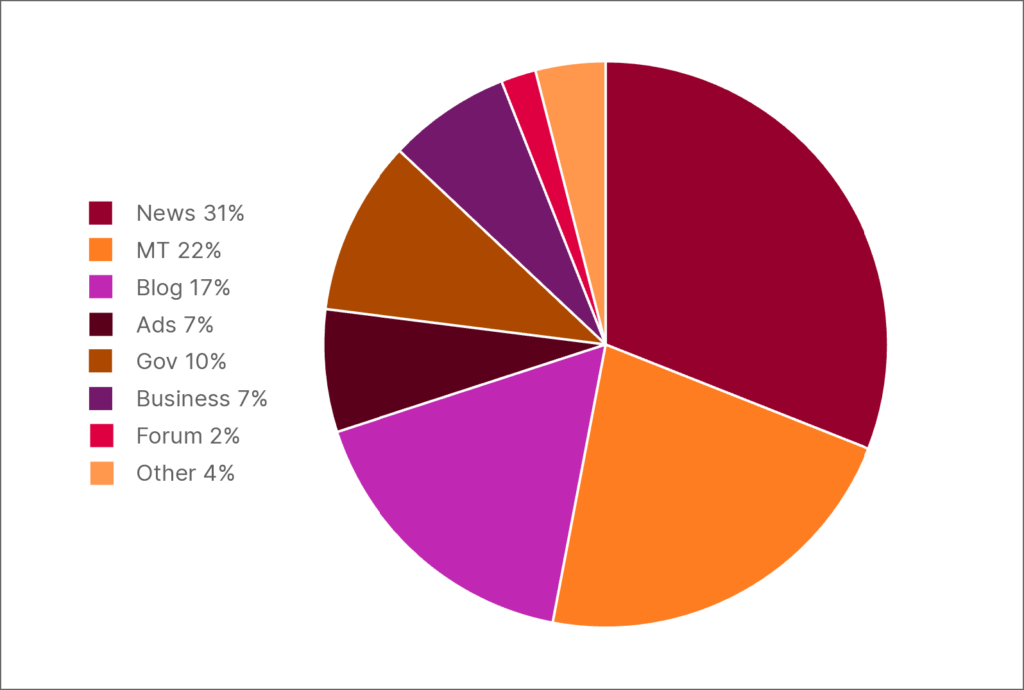
Nozaru sadalījums 300 visbiežāk lietotajos augšējā līmeņa tīmekļa domēnos atrastajā HPLT-v2 latviešu valodas datu daļā
Dezinformācijas radītās problēmas
Neskaitot neatbilstošu tulkojumu, kā arī nekorektu valodas stilistiku un gramatiku publiski pieejamajās datu kopās, mēs konstatējām nopietnas satura problēmas. Pētot datus no daudziem šķietami nevainīgiem avotiem, bieži atklājām LVM apmācības mērķiem nepiemērotu saturu. Līdz ar to mums nācās pēc saviem ieskatiem izvērtēt, vai saturs ir atbilstošs vai nav. Tādus materiālus kā pornogrāfija ir viegli identificēt, un ir vienkārši pamatot to izslēgšanu: pornogrāfija nesniedz jēgpilnu devumu LVM valodas izpratnei. Cita veida nevēlamo saturu atpazīt ir daudz grūtāk un laikietilpīgāk, bet ar šādu saturu apmācīti modeļi rada nopietnas ētiskas problēmas un drošības riskus.
Ievērību prasa saturs ar politisku nokrāsu, it īpaši no Krieviju atbalstošiem mediju avotiem, kas ietver pret Rietumiem un pret LGBT vērstu vēstījumu, prokrievisku noskaņojumu un pret Ukrainu vērstu propagandu. Daudzas šādas vietnes ES valstīs ir aizliegtas,. pateicoties darbam, ko veic uzraugošās organizācijas, t.sk. Latvijas Nacionālā elektronisko plašsaziņas līdzekļu padome, kura aizliegto vietņu sarakstu ir publicējusi, atvieglojot to izslēgšanu no LVM apmācības datiem. Darba gaitā lielākas grūtības sagādāja daudzi prokrieviskie serbu mediji. Lai arī ES valstīs neviens no tiem nav aizliegts, mēs konstatējām, ka daudzas no šīm vietnēm publicē tendenciozus nostāstus jeb “ekspertu viedokļus”, kam pievienotas MI ģenerētas fotogrāfijas, lai izplatītu Kremļa naratīvu par Rietumu militāro agresiju.

Piemēram, Serbijas prokrievisko mediju vietne, kas viltus ziņu izplatīšanai izmanto viltus attēlus. Nosaukums: “Polijas ceļus pārpludina NATO militārie konvoji: Ļebedevs atklāj šokējošus plānus!”
Šādi materiāli ir problemātiski ne tikai to politiskās neobjektivitātes dēļ, bet arī tāpēc, ka tajos meli ir pasniegti kā fakti (it īpaši tādās jomās kā vēsture, medicīna un sociālie jautājumi), ar mērķi eiropiešu vidū radīt domstarpības. Šādu datu izmantošana LVM apmācīšanā var pastiprināt kaitīgus stereotipus un maldinošu informāciju, tādējādi apdraudot modeļa objektivitāti un lietderību praksē.
Kvalitatīvu datu nepieciešamība
Ir skaidrs, ka efektīva LVM izveidošanai ir nepieciešams kas vairāk par milzīgu teksta apjomu; tam ir vajadzīgas ļoti kvalitatīvas, daudzveidīgas un uzticamas datu kopas. LVMapmācībai mums ir nepieciešami dati, kas modeļiem dod signālu apgūt kultūras kontekstu un sarežģītu argumentāciju. Kā rāda iepriekšējie piemēri, ir naivi vienkārši paļauties uz miriādēm tīmekļa datu.
Diemžēl valodās, kas nav angļu valoda, daudzas kvalitatīvas datu kopas ir mazas vai sadrumstalotas.
LVM apmācības specifika pieprasa garus teksta fragmentus, kas palīdzētu modeļiem aptvert stāstījuma plūsmu un kontekstu. Bez tiem LVM valodas “izpratne” paliek virspusēja; īsi fragmenti, lai cik labi tie būtu uzrakstīti, nenodrošina komplicēta modeļa apmācībai nepieciešamo dziļumu.
Piemērotu tekstu pieejamību papildus apgrūtina licencēšanas ierobežojumi.
Esam konstatējuši, ka diemžēl daudzos valstu valdību finansētos akadēmiskajos projektos ir izveidoti teikuma līmeņa korpusi, ko LVM apmācībai izmantot nevar konteksta trūkuma dēļ. Turklāt lielākā daļa šādu resursu ir paredzēti tikai akadēmiskiem pētījumiem un nav pieejami komerciālai izmantošanai, tāpēc komercpētnieki ir spiesti neizvēlīgi izmantot publiski pieejamos datus un paļauties tikai uz tiem.
Nekvalitatīvu datu izmantošana ietekmē ne tikai LVM veiktspēju. Tā var ietekmēt arī mūs un mūsu valodu. MI ģenerētais saturs kļūst aizvien izplatītāks e-pasta vēstulēs, rakstos un mārketinga materiālos, ietekmējot valodas lietojumu un uztveri. Ņemot vērā, ka šiem rīkiem labi padodas atpazīt un kopēt valodas nianses, vērienīga MI ģenerētu kļūdainu tekstu izmantošana laika gaitā normalizē pareizrakstības kļūdas vai neatbilstošu teikuma uzbūvi, potenciāli nivelējot valodas kā nācijai kopīgas skaņu un leksiski gramatisko līdzekļu sistēmas īpatnības un mazinot valodas bagātību.
Eiropas sadarbība ceļā uz labāku MI
Līdztekus norādītajām problēmām ir iepriecinoši sekmīgas sadarbības piemēri ar datu devējiem, kuri palīdz risināt šos jautājumus, nodrošinot ļoti kvalitatīvas, kuratoru pārraudzītas datu kopas. Mūsu pirmais partneris — Igauņu valodas institūts (EKI, Estonian Language Institute) — ir proaktīvi rīkojies, lai igauņu valoda būtu labi pārstāvēta MI apmācībā. Piedāvātajos resursos EKI ir ietvēris daudzveidīgus materiālus, tostarp literāros darbus un valsts pārvaldes publikācijas. Šīm datu kopām ir nenovērtējama nozīme LVM apmācībā, sekmējot gan formālās, gan neformālās valodas apguvi un ļaujot izveidot rīkus, kas lietotājam sniedz lielāku izteiksmes precizitāti un izpratni par kultūras nianšu daudzveidību.
Otrs pozitīvs piemērs ir Polijas vietējo kopienu organizācija SpeakLeash, kuru vada brīvprātīgie un kura veido un kataloģizē īpaši izstrādātas datu kopas poļu valodas atbalstam MI rīkos.
Abas organizācijas ir devušas vērtīgu ieguldījumu TildeLM modeļa attīstībā, palīdzot nodrošināt Baltijas un Austrumeiropas valodu niansētu reprezentāciju. EKI un SpeakLeash nav vienīgās organizācijas, kas sniegušas atbalstu. Citu organizāciju skaitā jāmin Somijas Nacionālā bibliotēka, Slovākijas Zinātņu akadēmijas Ļudovīta Štūra (Ľudovít Štúr) lingvistikas institūts, Slovēnijas Valodas modeļa iniciatīva, Zagrebas Universitātes Humanitāro un sociālo zinātņu fakultāte un Komenska Universitāte Bratislavā (Univerzita Komenského v Bratislave).
Šādas iniciatīvas parāda, kā vietējās kopienas un organizācijas var aktīvi gādāt, lai to valodu mantojums tiek saglabāts digitālā formā.
Kas notiks tālāk
Grūtības, ar kādām esam saskārušies, izstrādājot TildeLM, sākot ar vienkāršiem kvalitātes jautājumiem un beidzot ar mūsdienu viltus ziņu un propagandas sērgu, uzskatāmi liecina, ka pieeja “vairāk ir labāk” ir kļūdaina jau pašos pamatos. Nav iespējams pārbaudīt vārdu triljonus lielajās datu kopās, turklāt šī problēma ar katru dienu kļūst arvien komplicētāka. Turklāt LVM turpmākā virzība acīmredzami nav rodama arvien lielāku datu apjomu apkopošanā, jo paredzams, ka tuvāko pāris gadu laikā mums aptrūksies pieejami augstas kvalitātes dati.
Tikai laiks rādīs, vai MI nākotne balstīsies pārdomātā sadarbībā starp tehnoloģiju uzņēmumiem, akadēmiskajām institūcijām un kultūras organizācijām. Iedrošinošās partnerības ar tādām organizācijām kā EKI un SpeakLeash apliecina, ka šāda sadarbība ir īstenojama. Tagad mums ir jāvēro, vai šis process var kļūt par kaut ko vairāk nekā atsevišķi veiksmes stāsti un vai pastāv iespēja izveidot kvalitatīvākus LVM, tos apmācot ar mazākām, uzticamākām datu kopām. Atbilde uz šo jautājumu var izšķirt, vai MI patiesi var kalpot visām valodām un kultūrām vienlīdz labi.


