Latvijas valodu tehnoloģiju uzņēmums Tilde publiskojis atvērtā koda lielo valodas modeli (LVM) TildeOpen LLM – mākslīgā intelekta (MI) risinājumu, kas specializējas teksta ģenerēšanā Eiropas valodās. Unikālais LVM, kura izstrādi Tildei uzticējusi Eiropas Komisija, ir brīvi pieejams ikvienam interesentam. Tas sniedz iespēju uz TildeOpen bāzes veidot specializētus, konkrētiem uzdevumiem pielāgotus modeļus, kas teicami darbosies Eiropas mazo valstu valodās.
Jaunais lielo valodu modelis – precīzāks un drošāks
Latvijas vadošo mākslīgā intelekta speciālistu izstrādātais LVM gan precīzāk ievēro mazo valodu gramatikas principus, gan ir drošāks. Izstrādātāji to var izvietot lokālā serverī, tādējādi gūstot pārliecību, ka visa LVM iesniegtā informācija paliks pašu telpās vai drošā mākoņkrātuvē. Populārie komerciālie valodas modeļi parasti ir bāzēti datu centros, kas atrodas ASV vai Āzijā, un ne vienmēr atbilst ES datu aizsardzības un datu privātuma politikas standartiem.
«Populārie komerciālie valodas modeļi, piemēram, ChatGPT, tiek pārsvarā apmācīti ar angļu valodas datiem, kas nozīmē, ka šajā valodā ģenerētie rezultāti būs kvalitatīvāki nekā citās, mazāk izplatītās valodās. Tas mēdz novest pie neveiklām teikuma konstrukcijām un vārdu kārtības, gramatikas kļūdām vai pat neprecīzi izmantotiem un tulkotiem terminiem. Šīs kļūdas kļūst īpaši labi pamanāmas, kad LVM izmanto sarežģītāku un specifiskāku uzdevumu veikšanai. Tieši tādēļ TildeOpen tika pielāgots Eiropas valodām, īpaši Baltijas, kā arī ukraiņu un turku valodām, kas bieži vien netiek pietiekami labi pārstāvētas esošajos LVM risinājumos. Tilde ir viens no nedaudzajiem uzņēmumiem Eiropā, kas, izmantojot superdatoru resursus un unikālu ekspertīzi MI jomā, spējis pilnībā patstāvīgi izstrādāt šādu pamata LVM,» jaunā modeļa priekšrocības skaidro Tilde vadītājs Artūrs Vasiļevskis.
Viņš uzsver, ka TildeOpen spēj prasmīgi pielāgoties LVM latviešu valodai, tādēļ tā izmantošanu vajadzētu apsvērt kā valsts pārvaldei un pašvaldībām, tā vietējiem uzņēmumiem un mācību iestādēm. Tas arī ir viens no Eiropas Komisijas uzstādījumiem – ES izstrādātājiem veidot MI produktus lietošanai iekšējā tirgū, kā arī glabāt tos drošos resursos Eiropā, kas ievēro ES datu drošības direktīvas un standartus.
Eiropas superdatori – mākslīgā intelekta trenēšanai mazajās valodās
ES ir 24 oficiālās valodas un vairāk nekā 60 reģionālās, taču pasaulē populārāko LVM izstrādātāji fokusējas uz lielākajām valodām, mazākās atstājot novārtā. Eiropai šī pieeja neder, jo tā dēvētajās mazajās valodās runā vairāk nekā 200 miljoni eiropiešu jeb gandrīz puse no visiem. Lai veicinātu Eiropas globālo konkurētspēju MI jomā, ES izsludināja Large AI Grand Challengekonkursu, par kura uzvarētāju 2024. gada jūnijā tika pasludināts viens no Eiropas līderiem MI nodrošinātās valodu tehnoloģijās – Latvijas uzņēmums Tilde.
Uzvara deva iespēju izmantot divus miljonus grafisko procesorstundu (GPU) uz ātrākā superdatora Eiropā – LUMI. Šīs stundas tika piešķirtas tieši TildeOpen izstrādei. Šogad Tilde kļuva arī par vienu no pirmajiem uzņēmumiem, kam tika ļauts strādāt ar nupat atklāto JUPITER – jauno, šobrīd ātrāko superdatoru Eiropā. Pateicoties šo iekārtu jaudai, TildeOpen pirmo versiju izdevies izstrādāt aptuveni gada laikā.
Vairāk nekā 30 miljardu parametru lielais LVM tika apmācīts ar milzīgu daudzumu vispārīgas informācijas no dažādiem avotiem, veidojot bāzes modeli. Šo bāzi lietotāji var pielāgot specifisku uzdevumu veikšanai, piemēram, veidot kādā no Eiropas valodām ļoti labi runājošu MI asistentu.
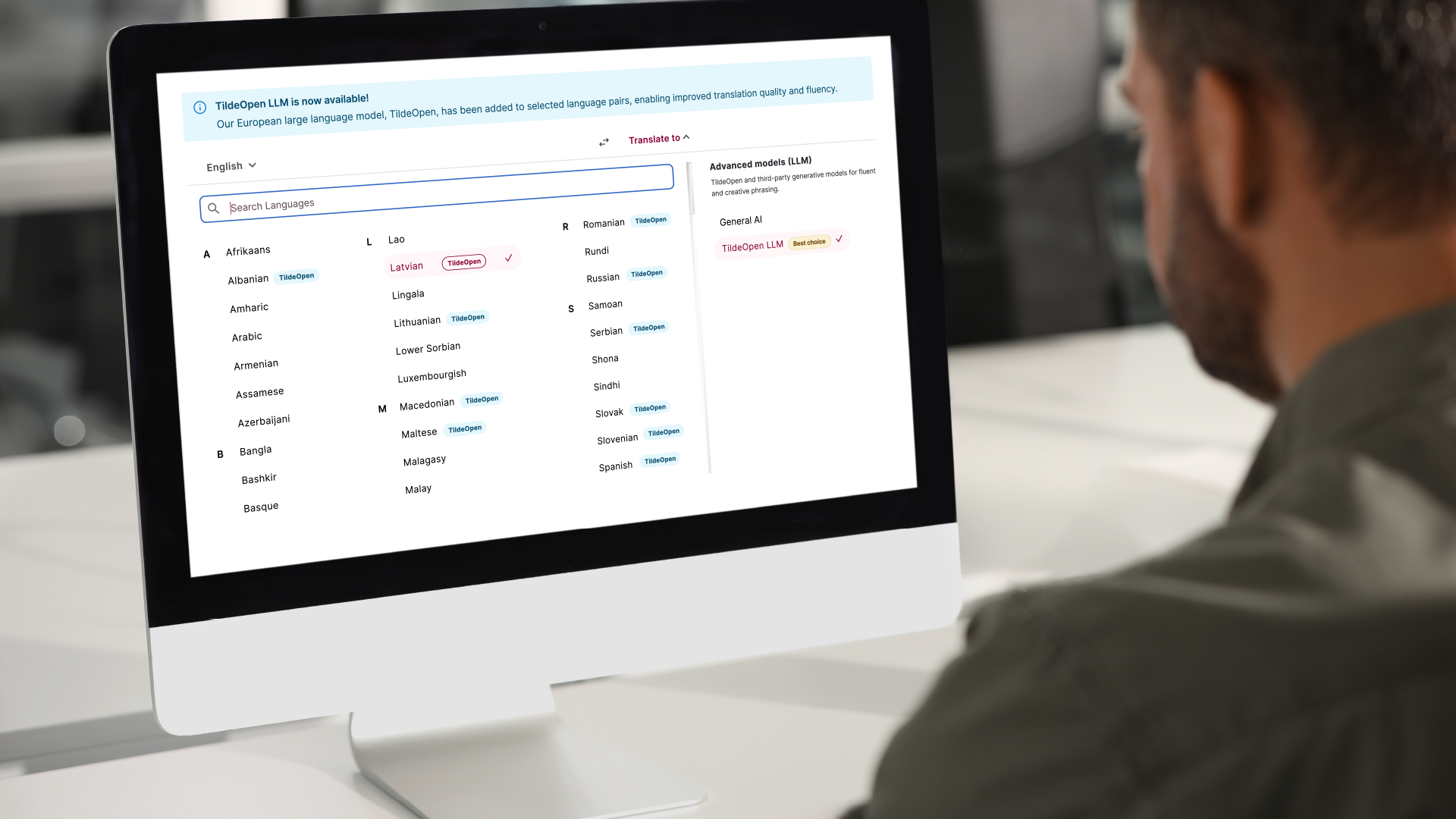
TildeOpen ir atvērtā koda risinājums un tas ir brīvi pieejams valsts iestādēm, uzņēmumiem, zinātniekiem, studentiem, medicīnas iestādēm, finanšu un apdrošināšanas nozarēm, lai tās varētu izmantot modeli atbilstoši nozares vajadzībām.
Modeli var droši viesot gan lokālajā serverī, gan mākoņkrātuvē, un tas ir pielāgots tām Eiropas valodām, kuras bieži vien ir nepietiekami pārstāvētas populārākajos risinājumos.
Tildeopen tika apmācīts LUMI superdatorā, izmantojot AMD Instinct ™ MI250X paātrinātājus. AMD aparatūras izmantošana atbalstīja plaša mēroga apmācību, kas nepieciešama, lai izveidotu 30 + miljardu parametru modeli Eiropas valodām.
Tildeopen LVM versija 1 ir izlaista platformā Hugging Face.