Mēs visi esam pieraduši pie valodu tehnoloģijām, kas palīdz mums ikdienas aktivitātēs, bet kā ir ar tiem laikiem, kad tās neizdodas? Šajā emuāra rakstā mūsu MI vecākais virsnieks Mārcis Pinnis skaidro, kā mēs izstrādājam valodu tehnoloģijas, kāpēc tās dažkārt cīnās un kādi ir to iemesli.
Bet vispirms... kas ir valodu tehnoloģijas?
Valodas tehnoloģija ir jebkurš risinājums, kas analizē, rada, modificē cilvēka tekstus un runu vai reaģē uz tiem. Ja jums ir viedtālrunis vai dators, jūs izmantojat valodu tehnoloģijas. Visiem mūsu modernajiem sīkrīkiem ir valodas tehnoloģijas, kas palīdz mums ātrāk piekļūt informācijai vai būt produktīvākiem. Piemēram, viedtālruņiem ir valodu tehnoloģiju iespējas, lai atpazīstiet savu runu, veikt dokumenta vai tīmekļa meklēšanu, veikt optisko rakstzīmju atpazīšanu (citiem vārdiem sakot, atpazīt tekstu digitālajā attēlā) utt.

Kā attīstīt valodu tehnoloģijas?
Pirmkārt, mums ir iegūstiet piekļuvi valodas datiem, ko varam izmantot modeļu apmācībai. Bez datiem mēs neko nevaram attīstīt. Vienkārši sakot, valodas dati var būt jebkurš dokuments, kas satur tekstu, vai jebkurš audio vai video fails, kas satur runu.
Kad mums ir valodas dati, nākamais solis ir apmācīt modeļus, izmantojot iT. Mūsdienās lielākā daļa valodu tehnoloģiju tiek izstrādātas, izmantojot mašīnmācīšanos un mākslīgos neironu tīklus. Piemēram, mūsu mašīntulkošanas sistēmas ir apmācīti, izmantojot transformatora kodētāja dekodētāja modeļus no nulles. Mūsu nosaukto entītiju atpazīšanas, noskaņojuma analīzes un nolūka noteikšanas modeļus apmāca, pielāgojot pamatu modeļus konkrētiem pakārtotiem uzdevumiem.
Un visbeidzot, mēs izvietojam modeļus lietošanai. Atkarībā no klientu prasībām modeļus var izvietot lokālajā infrastruktūrā vai mākonī un padarīt pieejamus, izmantojot API, trešo pušu rīku spraudņus vai pielāgotus lietotāja interfeisus. Piemēram, mūsu mašīntulkošanas sistēmas ir pieejamas mūsu klientiem dažādos datorizētos tulkošanas rīkos, izmantojot spraudņus, translate.tilde.com platforma, kas ļauj lietotājiem tulkot teksta fragmentus, dokumentus un tīmekļa lapas, un nodrošina vienkāršu tiešsaistes datorizētu tulkošanas rīku, ko var viegli izmantot cilvēki, kuri nav iesaistīti tulkošanas nozarē; tam var piekļūt arī, izmantojot API.
Valoda nav konstante
Problēma, kas rodas saistībā ar šo procesu, ir tā, ka kad modelis ir apmācīts, tas jau sāk novecot, jo tas nebūs redzējis nekādus pašreizējos un turpmākos datus. Ikviens, kurš ir izmantojis ChatGPT, iespējams, ir saskāries ar atrunu, ka tas zina tikai par datiem līdz 2021. gadam (vai jaunākajos modeļos līdz 2023. gada aprīlim). Modelis nav atjaunināts pašreizējā valodas lietojumā.

Tā kā valodu dati ir vienīgais vissvarīgākais faktors valodu tehnoloģiju izstrādē, tie ir vainojami arī lielākajā daļā kļūdu, ko parāda mūsu modeļi. Tāpēc ir ļoti svarīgi, lai, izstrādājot valodu tehnoloģijas, mums būtu pietiekami daudz datu, dati būtu tīri, tie būtu aktuāli un pareizajā jomā.
To ir ļoti grūti panākt, lai gan valodu dati, ko mēs izmantojam, bieži vien ir novecojuši. Tātad, kā valodas dati var novecot? Aplūkosim dažus piemērus.
#1 sabiedrības uzmanība ir mainīgs faktors
Šeit redzams piemērs tam, kā laika gaitā mainās divu vārdu lietojums Latvijas ziņās.

Tas parāda, ka sabiedrības uzmanība laika gaitā mainās, kas nozīmē, ka ir jāmaina arī tēmas, kuras mūsu valodu tehnoloģijām ir jāatbalsta un jārisina. Vakar tas bija COVID-19, šodien tas ir karš Ukrainā. Rīt būs vēl viena nezināma tēma. Ja mēs saglabājam tehnoloģijas statiskas, tās ļoti ātri kļūst novecojušas.
#2 valoda kļūst bagātāka
Valoda mainās arī tāpēc, ka cilvēki bieži ievieš tajā jaunus jēdzienus. Piemēram, Latvijas Zinātņu akadēmijas terminoloģijas Komisija regulāri ievieš jaunu terminoloģiju.

Valodu tehnoloģiju sistēmas nekad nebūs redzējušas tās datos. Neviena tulkošanas sistēma nespēs tos apstrādāt, pirms tehnoloģiju izstrādātāji apkopos datus un atkārtoti apmācīs modeļus vai vismaz piemēros dažas izpildlaika pielāgošanas metodes.
#3 valoda nepārtraukti mainās
Cilvēki arī maina esošos jēdzienus. Piemēram, kā parādīts tālāk redzamajā piemērā, mainot esošo terminu tulkojumus.

Ja tulkošanas sistēmas datos ir šie termini ar iepriekšējiem tulkojumiem, visi dati ir jārediģē, lai tie būtu atjaunināti.
#4 Jaunas koncepcijas sabiedrībā
Sabiedrība laika gaitā mainās, radot citas atšķirības valodas lietošanā. Piemēram, viena vērā ņemama izmaiņa, kas rada problēmas valodu tehnoloģiju izstrādātājiem, ir dzimumneitrālas valodas ieviešana. Šīs izmaiņas ir lēnām ieviestas arvien vairāk valodās. Tomēr datos, uz kuriem paļaujamies, tie nav iekļauti. Šī īpašā parādība liek mums vai nu ieviest noteikumus savās sistēmās, vai ģenerēt sintētiskus datus.
#5 Globālie notikumi
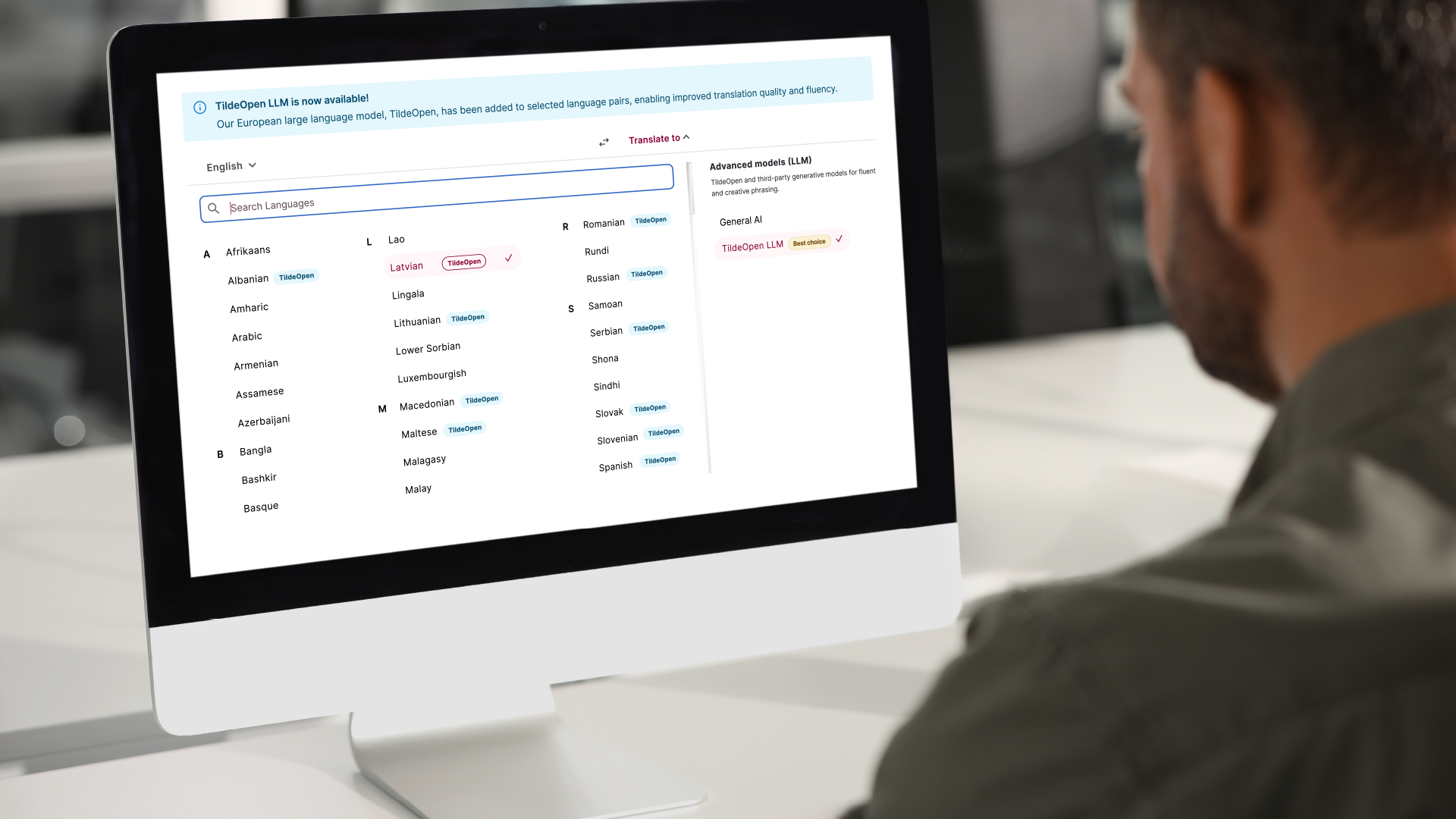
Notikumiem, kas ietekmē sabiedrību, var būt nepieciešamas arī izmaiņas valodas lietojumā. Piemēram, Krievijas karš Ukrainā lika Latviešu valsts valodas centram nolemt, ka 31 Ukrainas pilsēta un pilsētas nosaukums latviešu valodā tiks tulkots atbilstoši sākotnējam Ukrainas (nevis krievu) formulējumam.
Lai to paveiktu, mums Tildē bija vai nu jārediģē visi mūsu dati, vai jāizmanto adaptīvas metodes, kas ļāva pielāgot atsevišķu vārdu vai frāžu tulkojumus.
#6 valoda ir dabiski neskaidra un reti sastopama
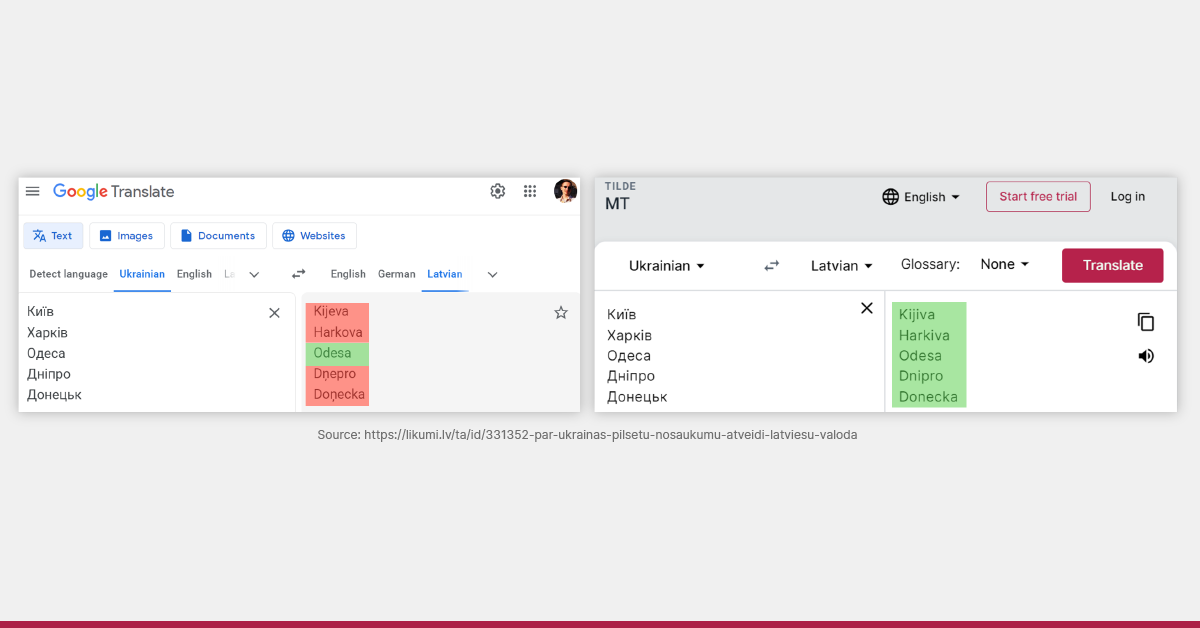
Pat ja valodas tehnoloģiju izstrādātājs neatpaliks no pārmaiņu tempa, viņš nekad nespēs aptvert visus leksikus valodā. Vienkārši ir pārāk daudz vārdu, atrašanās vietu, organizāciju un nišas tēmu terminu, lai aptvertu visu. Viens no piemēriem ir Baltijas vienības diena, kas nesen tika atcerēta Latvijā un Lietuvā. Mūsu ārlietu ministrs tvītoja sveicienu Lietuvas kolēģim, un cilvēki pamanīja, ka tulkojums angļu valodā nav pilnīgi precīzs, jo “Balto vienotību” tulkoja “Balto vienotību”.
Kāpēc tas notika? Vārds “balta” var būt neskaidrs (tas var nozīmēt “balta” vai “Baltijas”). Un, ja tulkošanas sistēmas datos nav frāzes “Baltu vienība”, kā sistēma var zināt, ka šāda lieta pastāv? Tieši tā notika – dati neietvēra šo notikumu.
#7 valodu dati bieži vien ir vērsti uz angļu valodu
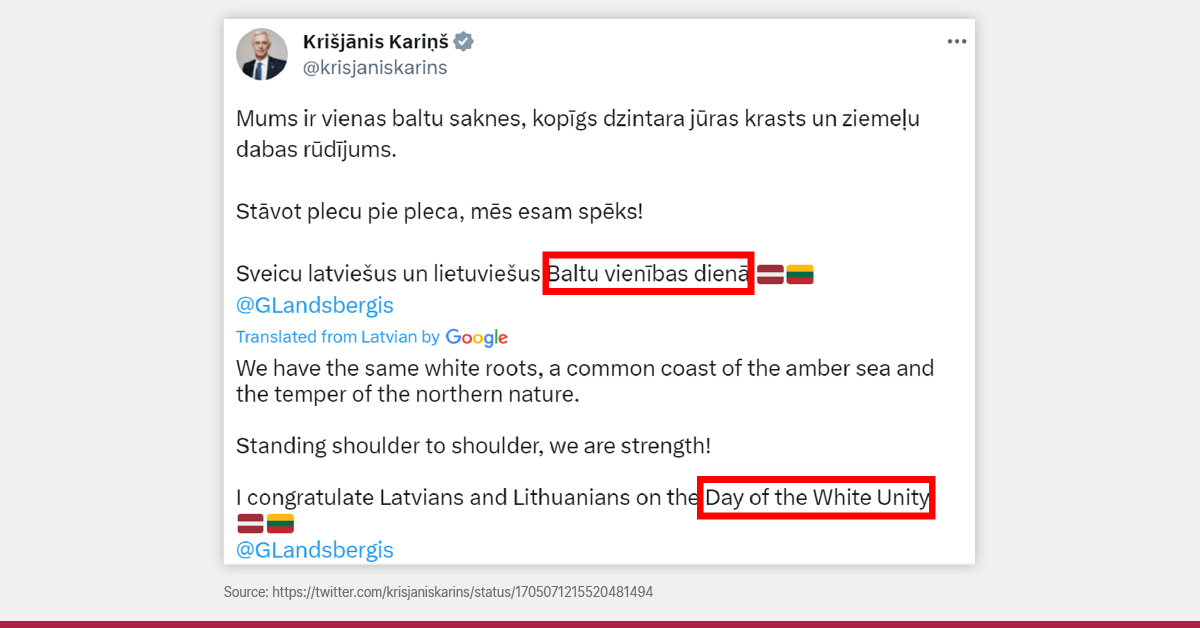
Mūsu rīcībā esošo datu angliski centrētais raksturs var radīt problēmas. Lielākā daļa pieejamo datu ir radīti, tulkojot saturu no angļu valodas citās valodās un daudz mazāk citos virzienos. Tas nozīmē, ka ar šādiem datiem apmācītā sistēmā nekad nebūs iekļauta nejauša persona no vietas ārpus ASV vai Apvienotās Karalistes. Un, ja šī persona ir jūs (vai kāds no mums), tad tā kļūst diezgan personiska. AI kļūst personisks!
Piemēram, es esmu arī šāda “nejauša persona”, un, ja es tulkoju kaut ko, kas ietver manu vārdu, izmantojot Google Translate, es varu sagaidīt, ka mans vārds tiks sajaukts un apstrādāts nekonsekventi. Tomēr šo problēmu var risināt, izstrādājot sistēmas, kas var apstrādāt vietējās nosauktās entītijas.
Kā mēs kā izstrādātāji sekojam līdzi valodas izmaiņām?
Pirmkārt, mēs nekad nepārstājam vākt datus. Kad tu apstājies, tu jau esi novecojis. Mēs arī cenšamies piegādāt savus modeļus iteratīvi, tostarp klientiem, kuri pasūta pielāgotas sistēmas (iesakām pārkvalificēt sistēmas vismaz divreiz gadā).
Tad, mēs veicam daudz pētījumu par atsaucīgām un adaptīvām metodēm, kas ļauj viegli pielāgot sistēmas izpildlaikā bez nepieciešamības atkārtoti apmācīt modeļus. Piemēram, mūsu MT sistēmās varat pievienot savu terminoloģiju, kā arī nosauktās entītijas. Un mūsu ASR sistēmās jūs varat pievienot savu specifisko vārdnīcu.
Un ko jūs varat darīt?
Ja esat valodas tehnoloģijas lietotājs, varat darīt daudz, lai palīdzētu uzlabot sistēmas jūsu labā, proti, koplietot valodas datus. Tomēr, lai to izdarītu, jūsu organizācijā ir jābūt izveidotiem labiem datu pārvaldības procesiem. Ja jums ir grūtības ar valodas datu pārvaldību, konsultējieties ar mums, lai saņemtu padomus par labāko praksi. Apsveriet arī iespēju atklāti kopīgot savus datus, ja vēlaties izmantot labākus “bezmaksas” pakalpojumus saviem nišas domēniem. Lai kopīgotu datus, izmantojiet bezmaksas publiskos datu kopīgošanas pakalpojumus, piemēram, ELRC KOPĪGOŠANU vai Eiropas valodu tīklu.
Tāpēc noslēgumā mēs visi izmantojam valodu tehnoloģijas. Tie ļauj mums būt produktīvākiem, piekļūt lielākai informācijai un sasniegt plašāku auditoriju. Valodu tehnoloģijas nekad nebūs 100% precīzas, jo valodas ir sarežģītas un pastāvīgi mainās. Tomēr, ja mēs izstrādājam sistēmas tā, lai mēs sagaidītu pastāvīgas izmaiņas, mēs varam efektīvi mazināt kļūdas un, iespējams, padarīt mūsu klientus mazliet laimīgākus.