Suurte keelemudelite andmedilemma: põhjatu sopalaugas või kindlapiiriline kullasoon?
Tilde meeskond 22. jaanuar 2025
Esitaja (d): dr Toms Bergmanis, Tilde AI teadur
Inimkeelt mõistvate ja genereerivate tehisintellektisüsteemide loomine nõuab tohutul hulgal keeleandmeid. Just andmed annavad suurele keelemudelile (LLM ehk large language model) võime inimkeelt mõista ja luua. Kuid siinkohal peab kahjuks paika kulunud väljend „andmetel ja andmetel on vahe“. Ja seesama vahe eristab toimivat mudelit kasutust.
Euroopa ja Ameerika viimatiste LLM-ide mudelikaartide põhjal hinnates on LLM-ide treenimiseks saadaval suur hulk teksti. Tegelikkuses sisaldab see tekstihulk kvaliteetseid ja korralikult kureeritud andmeid võrdlemisi vähesel määral, samas kui põhimass saadakse oportunistlikult veebi koorides.
Tilde mitmekeelse aluskeelemudeli TildeLM-iarendamisel on teada-tuntud vanasõna „mida külvad, seda lõikad“ kujunenud reaalseks probleemiks. Ühest küljest prognoosime, et vajame 30 miljardi parameetrise aluskeelemudeli treenimiseks ligikaudu 600–700 miljardi sõna suurust andmestikku. Aga teisest küljest tundub, et iga esmapilgul kullasoonena näiv tekstikogum osutub kohe, kui hakkame selle kvaliteeti uurima, hoopis Pandora laekaks.
Praeguste andmestike kitsaskohad
Enamik LLM-ide treenimiseks saadaolevaid andmeid pärineb kahest põhiallikast: Common Crawl ja Internet Archive. Tegu on kahe andmehoidlaga, mis luuakse miljonitelt veebilehtedelt teabe koorimise teel. Kuigi need allikad sisaldavad hulgaliselt materjali, on neil ka märkimisväärseid puudujääke, eriti kui võrrelda inglise keelt kõigi teiste keeltega.
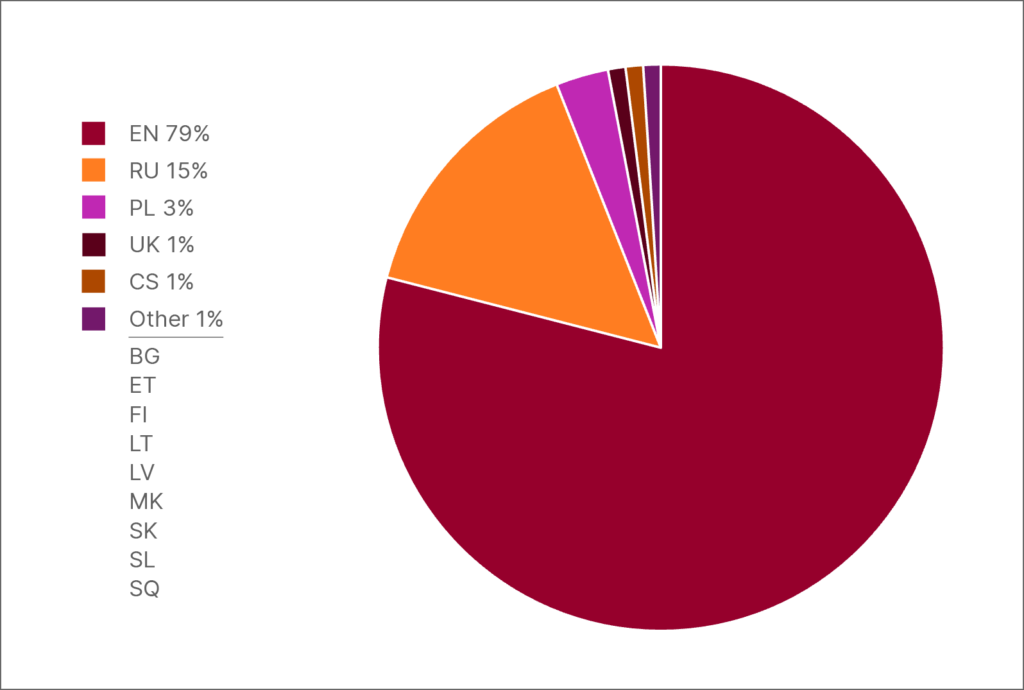
Andmete jaotus HPLT-v2 andmestikus: inglise keel võrreldes 13 keelega, mida räägib kokku üle 250 miljoni inimese
Inglise keel on ülekaalus andmestikust sõltumata. Inglise keele sõnade arv ei ole igas andmestikus peajagu üle üksnes mis tahes üksikkeele sõnade arvust, vaid lausa tervete geograafiliste piirkondade kõigi keelte sõnade koguarvust. See on peamine põhjus, miks praegu on enamiku LLM-ide treenimiseks kasutatavatest andmetest üle 90% inglise keeles, millest tulenevalt on paljud keeled alaesindatud. See lahknevus põlistab inglise keele kesksust, mis kajastub tehisintellektimudelites, mis valdavad inglise keelt laitmatult, ent jäävad teistes keeltes hätta nii keeleliste eripärade kui ka kultuuriliste varjunditega. Alaesindatud keelte kõnelejaile tähendab see kehvema kvaliteediga tehisintellekti tööriistu ja piiratud juurdepääsu tipptasemel tehnoloogiale.
Lisaks inglise keele arvulisele ülekaalule on märkimisväärne osa muukeelsest tekstist ebakvaliteetne masintõlge. Näiteks, kui uurisime HPLT-v2 lätikeelsetes andmetes 300 kõige sagedasemat ülataseme veebidomeeni, avastasime, et lausa 25% neist on mahukad masintõlgitud veebilehed..
Probleemiks pole vaid tõlgete kehv kvaliteet, vaid ka tõsiasi, et tõlkeid ei peeta üldjuhul heaks keele-etaloniks, kuna tavaliselt matkivad need liigselt oma lähtekeelt. Tõlkekeeles ja esineda ebaloomulikku sõnastust ja grammikavigu ning selles võib kaotsi minna kultuuritaust . Seetõttu ei pruugi tõlkekeele põhjal treenitud tehisintellektimudelid vastavat keelt õigesti mõista ega selles ilmekat sisu genereerida.
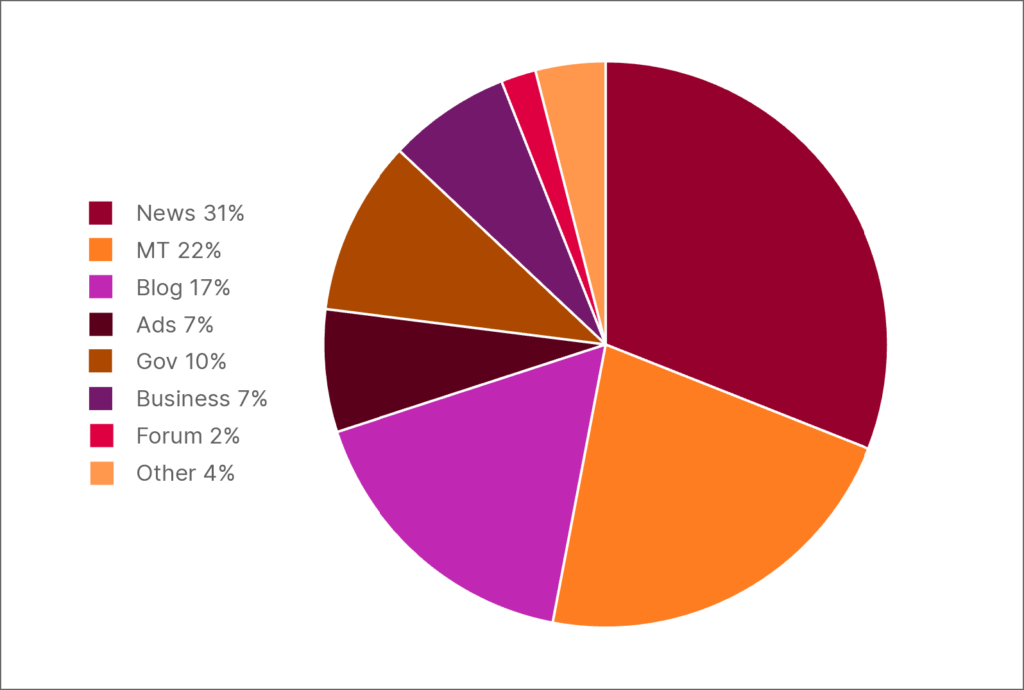
HPLT-v2 lätikeelsetes andmetes 300 kõige sagedasema ülataseme veebidomeeni domeenisiltide jaotus
Erapoolikuse ja väärinfoga seotud probleemid
Peale silmatorkavate kitsaskohtade, nagu grammatikavead või keelenormide eiramine, oleme avastanud ka palju murettekitavamaid probleeme. Uurides näiliselt usaldusväärsetest allikatest pärinevaid andmeid, leidsime sisu, mis oli meie treenimiseesmärkide suhtes sobimatu või asjakohatu. Nii tuli meil sageli oma äranägemise järgi otsustada, kas sisu on vastuvõetav või mitte. Kerge on tuvastada näiteks pornograafiat jms materjali ning õigustada selle väljajätmist: pornograafia lihtsalt ei panustaks olulisel määral keele mõistmisesse. Aga palju keerulisem on tuvastada muud sisu, mille abil treenitud mudelitega kaasneksid eetika- ja turvaprobleemid.
Näiteks tasub märkida poliitiliselt kallutatud sisu, eriti venemeelsetest meediaallikatest. Sellist sisu iseloomustavad tihti jõulised Lääne- ja LGBT-vastased narratiivid, venemeelsus ning Ukraina-vastane propaganda.. Paljud seda liiki saidid on ELis keelatud tänu selliste organisatsioonide jõupingutustele nagu Läti riiklik elektroonilise massimeedia nõukogu, mis on avaldanud ka keelatud saitide nimekirja, mis tegi nende väljajätmise lihtsaks. Suur osa venemeelset Serbia meediat osutus raskemaks katsumuseks. Kuigi ükski neist väljaannetest pole ELis keelatud, avastasime, et paljud saidid avaldasid kuulujutte või võltsfotodega kõrvutatud ekspertarvamusi, mille eesmärk oli levitada Kremli narratiivi Lääne sõjalisest agressioonist.

Serbia venemeelne meediasait kasutab valeuudiste levitamiseks võltsitud fotosid. Pealkiri: „Poola maanteed on NATO sõjakonvoidest umbes: Lebedev paljastas šokeerivad plaanid!”
Seda tüüpi materjal ei põhjusta probleeme üksnes poliitilise kallutatuse tõttu, vaid ka sellepärast, et eurooplaste seas konfliktide külvamiseks esitatakse selles valefakte, eriti ajaloo, meditsiini ja ühiskondlike küsimuste valdkonnas. Kui treenida nende andmete abil LLM-i, võib see põlistada kahjulikke stereotüüpe ja väärteavet ning seada ohtu mudeli objektiivsuse ja praktilise kasutatavuse.
Vajadus kvaliteetsete andmete järele
On selge, et efektiivse LLM-i loomiseks ei piisa vaid üüratust tekstimassiivist, vaid see nõuab kvaliteetseid, mitmekesiseid ja usaldusväärseid andmestikke. LLM-idetreenimiseks läheb meil tarvis andmeid, mis annavad mudelitele kultuuriruumi ja keerukate arutluskäikude tundmaõppimiseks vajaliku signaali. Nagu eelnevad näited on demonstreerinud, oleks veebist kokkukuhjatud andmetele tuginemine lihtsameelne.
Kahjuks on muudes keeltes (peale inglise keele) suur osa kvaliteetseid andmestikke väikesed või killustunud.
LLM-i treenimisviisist tulenevalt läheb vaja pikki tekstilõike, et mudel suudaks hoomata narratiivi sidusust ja konteksti. Muul juhul jääb LLM-i arusaamine keelest pinnapealseks. Isegi kõige paremini kirjutatud lühikeses tekstilõigus jääb vajaka viimistletud mudeli treenimiseks tarvilikust sügavusest.
Olukorda raskendavad ka litsentsipiirangud.
Samuti leidsime, et paljud riikliku rahastusega teadusprojektid on andnud tulemuseks lausepõhised tekstikorpused, mis on LLM-i treenimiseks kasutud. Lisaks on enamik sellistest allikatest ette nähtud puhtakadeemiliseks teadustööks ega ole kättesaadavad ärilisel eesmärgil kasutamiseks, nii et erasektoris tegutsevatel teadlastel on võimalik tugineda üksnes oportunistlikult hangitud andmetele.
Kuid tasub arvesse võtta, et ebakvaliteetsete andmete kasutamine ei mõjuta ainult LLM-i toimimist. See võib avaldada mõju ka meile endile ja keeltele. Kuna tehisintellekti genereeritud sisu levib e-kirjades, artiklites ning turundusmaterjalides järjest laialdasemalt, muudab see inimeste keelekasutust ja -taju. Tehisintellektipõhised tööriistad oskavad keelenüansse hästi tuvastada ja matkivad õpitut, a mis tähendab, et tehisintellekti genereeritud teksti laialdane kasutamine muudab praegu vigaseks või ebaloomulikuks peetava keelekasutuse aja jooksul inimeste silmis vastuvõetavaks ja ohustab seeläbi keele rikkust.
Euroopas tehtav koostöö parema tehisintellekti loomiseks
Nimetatud kitsaskohtadele vaatamata on meil ka julgustavaid näiteid koostööst andmedoonoritega, kes aitavad neid probleeme lahendada, pakkudes kvaliteetseid kureeritud andmestikke. Meie esimene partner oli Eesti Keele Instituut (EKI), mis tegutseb proaktiivselt selle nimel, et eesti keel oleks tehisintellekti treenimisel hästi esindatud. Meile oma allikaid pakkudes andis EKI meie kasutusse mitmekesiseid materjale kirjandusteostest riigiasutuste väljaanneteni. Need andmestikud on mudelite treenimisel hindamatu väärtusega, kuna aitavad mõista nii ametlikku kui ka kõnekeelt ning võimaldavad tööriistadel oma kasutajaid täpsemalt ja kultuuriteadlikumalt teenida.
Ka Poolas teeb poola keele säilimise nimel märkimisväärseid edusamme rohujuuretasandi organisatsioon SpeakLeash. Vabatahtlike ühendus SpeakLeash koostab ja katalogiseerib andmestikke, mis on spetsiaalselt ette nähtud tehisintellektipõhiste tööriistade keeleoskuse parandamiseks.
Mõlemad organisatsioonid on andnud väärtusliku panuse TildeLM-i, mis aitab tagada, et Baltikumi ja Ida-Euroopa keeled oleksid esindatud teistega võrreldava põhjalikkuse ning üksikasjalikkusega. EKI ja SpeakLeash ei ole ainsad organisatsioonid, mis on meile abikäe ulatanud. Meid on toetanud ka Soome rahvusraamatukogu, Slovakkia teaduste akadeemia Ľ. Štúri lingvistikainstituut, Sloveenia keelemudelialgatus, Zagrebi ülikooli humanitaar- ja sotsiaalteaduskond ning Bratislava Comeniuse ülikool.
Sellised algatused näitavad, et kohalikud kogukonnad ja organisatsioonid saavad oma keelepärandi digitaalsel kujul säilitamisel ise aktiivselt kaasa lüüa.
Mida toob tulevik?
TildeLM-i arendamisel esile kerkinud murekohad (alates lihtsamatest kvaliteediprobleemidest kuni tänapäeval katkuna levivate valeuudiste ja propagandani) lubavad järeldada, et põhimõte „mida rohkem, seda uhkem“ seisab keeleandmete puhul savijalgadel. Suurandmestike triljoneid sõnu on võimatu üle kontrollida ning nende sisu ja kvaliteediga seotud katsumused näivad iga päevaga järjest ületamatumad. Samuti on selge, et LLM-ide arendamise tulevik ei saa seisneda järjest mahukamate andmestike kokkuajamises, sest saadaolevad kvaliteetsed andmed ammenduvad eeldatavasti lähiaastatel.
Ainult aeg näitab, kas tuleviku tehisintellekt sünnib tehnoloogiaettevõtete, akadeemiliste asutuste ja kultuuriorganisatsioonide sisulise koostöö kaudu. Sellise koostöö võimalikkust näitlikustavad meie edukad partnerlussuhted selliste asutustega nagu Eesti Keele Instituut ja SpeakLeash. Nüüd tuleb vaadata, kas üksikutest edulugudest saab minna kaugemale ning arendada kvaliteetsemaid mudeleid, mille treenimine toimub väiksemate ja usaldusväärsemate andmestike põhjal. Selle küsimuse vastusest võib oleneda, kas tehisintellekt suudab kõiki keeli ja kultuure võrdselt teenida.

