
We’re all used to language technologies helping us in everyday activities, but what about those times when they fail? In this blog article, our Chief AI Officer, Mārcis Pinnis, explains how we develop language technologies, why they sometimes struggle, and the reasons behind it.
But first… what are language technologies?
A language technology is any solution that analyses, produces, modifies or responds to human texts and speech. If you have a smartphone or a computer, then you use language technologies. All our modern gadgets feature language technologies that help us access information faster or be more productive. For instance, smartphones have language technology capabilities to recognize your speech, perform a document or web search, perform optical character recognition (or in other words – recognize text within a digital image), etc.

How do we develop language technologies?
First, we need to get access to language data that we can use to train models. Without data, we can’t possibly develop anything. Put simply, language data can be any document containing text, or any audio or video file containing speech.
Once we have our language data, the next step is to train models using it. Nowadays, most language technologies are developed using machine learning and artificial neural networks. For instance, our machine translation systems are trained using transformer-based encoder-decoder models from scratch. Our named entity recognition, sentiment analysis, and intent detection models are trained by fine-tuning foundation models for specific downstream tasks.
And finally, we deploy models for use. Depending on customer requirements, the models can be deployed in local infrastructure or the cloud, and made accessible either through APIs, third-party tool plugins, or custom-built user interfaces. For instance, our machine translation systems are available for our customers in various computer-assisted translation tools using plugins, on the translate.tilde.com platform, allowing users to translate text snippets, documents and web pages, and provides a simple online computer-assisted translation tool that can be used easily by people who aren’t involved in the translation industry; it can also be accessed through API.
Language is not constant
The problem that arises with this process is that when the model has been trained, it already starts to become obsolete as it won’t have seen any current and future data. Everyone who has used ChatGPT has probably come across the disclaimer that it only knows about data till 2021 (or in the recent models till April 2023). The model is not up to date on current language use.

Since language data is the single most important factor when developing language technologies, it is also blamed for most errors that our models show. It is therefore critical that when we develop language technologies, we have enough data, the data is clean, it is current, and in the right domain.
This is very difficult to achieve though as the language data we use is often obsolete. So, how can language data become obsolete? Let’s look at some examples.
#1 The focus of society is a changing factor
Here you see an example of how the use of two words in Latvian news alters over time.

What this shows is that the focus of society changes over time, which means that the topics our language technologies need to support and handle also need changing. Yesterday it was COVID-19, today it is the war in Ukraine. Tomorrow, there will be yet another unknown topic. If we keep technologies static, they very quickly become obsolete.
#2 Language becomes richer
Language also changes because people often introduce new concepts into the language. For instance, the Terminology Commission of the Latvian Academy of Sciences regularly introduces new terminology.

Language technology systems won’t have ever seen them in the data. No translation system will be able to handle them before technology developers gather the data and re-train the models, or at least apply some run-time adaptation methods.
#3 Language keeps changing
People also alter existing concepts. For instance, as shown in the example below – by changing translations of existing terms.

If translation system data feature these terms with prior translations, all the data must be edited to keep it up to date.
#4 New concepts in society
Society itself changes over time, bringing about other differences in the use of language. For instance, one notable change that poses a challenge for language technology developers is the introduction of gender-neutral language. These changes have slowly been introduced in more and more languages. However, the data that we rely on does not feature them. This particular phenomenon makes us either introduce rules in our systems or generate synthetic data.
#5 Global events
Events affecting societies may also require changes in language use. For example, Russia’s war in Ukraine triggered the Latvian State Language Center to decide that 31 Ukrainian towns and city names in Latvian would be translated to follow the original Ukrainian (and not Russian) wording.
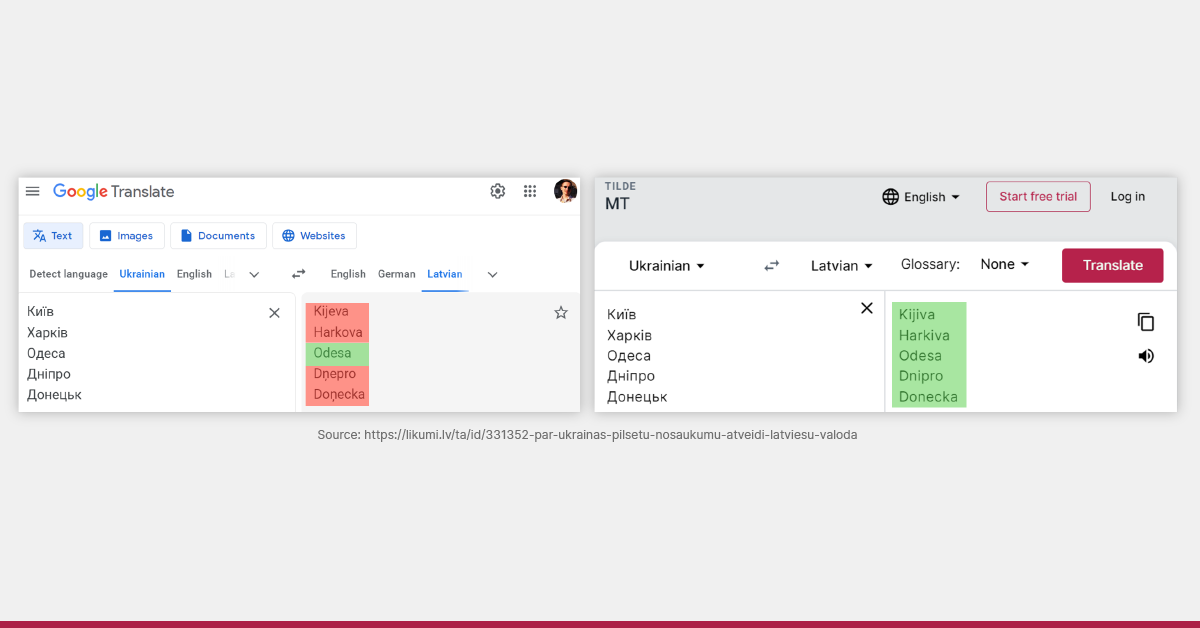
To handle this, we at Tilde had to either edit all of our data or use adaptive methods that allowed us to tweak translations of individual words or phrases.
#6 Language is naturally ambiguous and sparse
Even if a language technology developer keeps up with the pace of change, they will never be able to cover all the lexis in the language. There are simply too many names, locations, organizations and niche subject terms to cover everything. One example is the day of Baltic Unity, which was recently remembered in Latvia and Lithuania. Our minister of foreign affairs tweeted a greeting to the Lithuanian counterpart and people noticed that the translation in English wasn’t completely accurate as “Baltic Unity” was translated into “White Unity”.
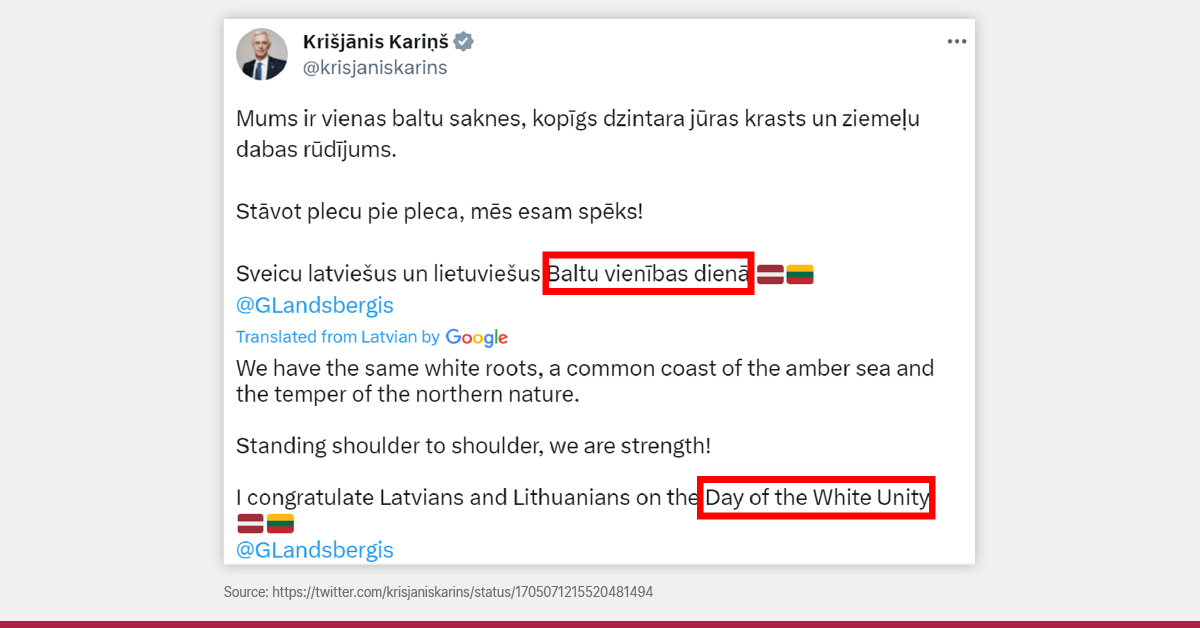
Why did this happen? The word “Baltu” itself can be ambiguous (it can mean “White” or “Baltic”). And if the translation system’s data does not feature the phrase “Baltic Unity”, then how can the system know that such a thing exists? This is what happened – the data did not feature this event.
#7 Language data is often English-centric
The English-centric nature of the data that we have can cause issues. Most available data has been created by translating content from English into other languages and much less in other directions. This consequently means that a system trained on such data will never have included a random person from someplace outside the US or the UK. And if that person happens to be you (or any of us) then it becomes quite personal. The AI becomes personal!
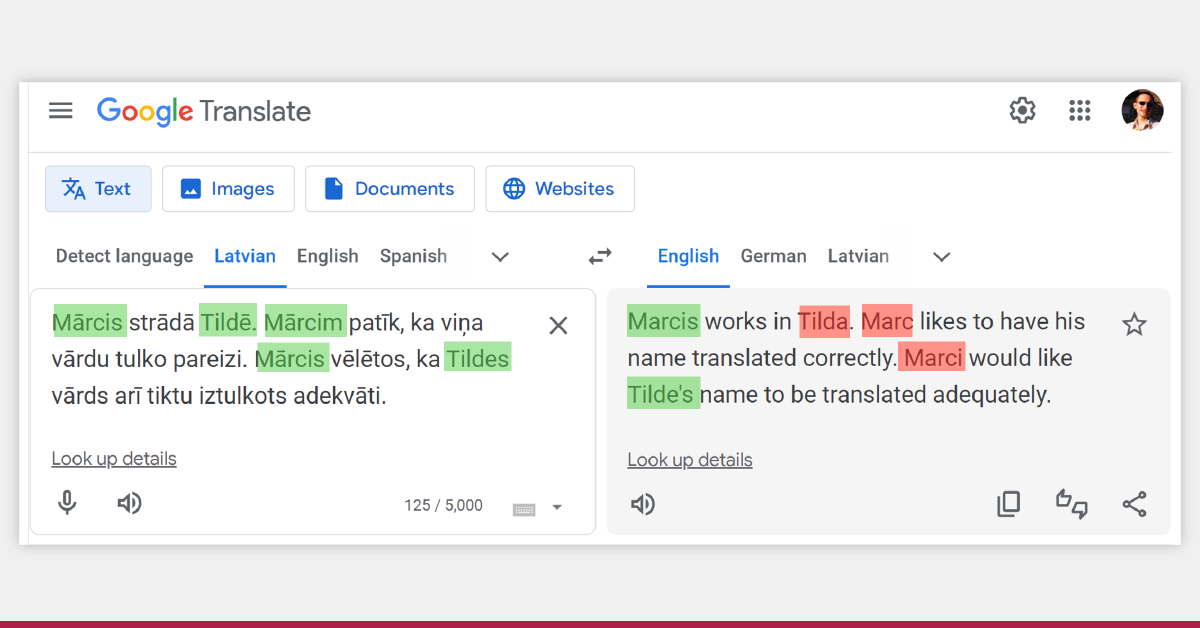
For instance, I am also such a “random person”, and if I translate something featuring my name using Google Translate, I can expect my name to be mistranslated and handled inconsistently. However, this issue can be addressed by developing systems that can handle local named entities.
How do we as developers keep up with changes in language?
First of all, we never stop collecting data. Once you stop you’re already becoming obsolete. We also try to deliver our models iteratively, including for customers who order custom systems (we recommend re-training systems at least bi-annually).
Then, we do a lot of research on responsive and adaptive methods that allow systems to be adjusted easily during runtime without the need to re-train models. For instance, in our MT systems, you can add your terminology as well as your named entities. And in our ASR systems, you can add your specific vocabulary.
And what can you do?
If you are a language technology user, you can do a lot to help improve systems to your benefit, and that is to share language data. However, to do this, you must have good data management processes established in your organization. If you struggle with language data management, consult us for advice on the best practices. Also, consider sharing your data openly if you want to benefit from better “free” services for your niche domains. To share data, use free public data-sharing services, such as ELRC-SHARE or the European Language Grid.
So, to wrap up, we all use language technologies. They allow us to be more productive, access more information, and reach wider audiences. Language technologies will never be 100% precise, as languages are complex and constantly changing. However, if we develop systems in a way that we expect constant changes, we can effectively mitigate errors and maybe make our customers a little happier.


 Hi, I am the Tilde chatbot. How can I help you?
Hi, I am the Tilde chatbot. How can I help you?