
Kas ir izguves papildināta ģenerēšana (RAG)?
Izguves papildināta ģenerēšana (Retrieval-Augmented Generation — RAG) ir kļuvusi par jaudīgu metodi, kas ļauj lielajiem valodas modeļiem (LVM) likt balstīties uz konkrētām jomām pielāgotu saturu. Pēc būtības RAG sistēmas ļauj lietotājiem indeksēt dokumentu kopumu un uzdot jautājumus par šo dokumentu saturu dabiskā valodā. Sistēma atbild uz vaicājumu, vispirms izgūstot šim vaicājumam atbilstošākos dokumentus un pēc tam liekot LVM ģenerēt atbildi, pamatojoties uz šo informāciju. Solījums ir vienkāršs: lietotāji var uzdot jautājumus paši par saviem datiem tā, it kā sarunātos ar lietpratēju, un sistēma sniedz kodolīgas, lietderīgas atbildes.
Lūk, piemērs, kā tas darbojas. Iedomājieties, ka jums ir liels apjoms uzņēmuma dokumentu un jums ir jāatrod viens pārskats, kurā ir uzskaitīti jūsu visvairāk pārdotie produkti pirms pieciem gadiem. Tā vietā, lai visi dokumenti jums būtu jāpārmeklē saviem spēkiem, jūsu viedais asistents atrod pareizo pārskatu, izlasa to un sniedz jums skaidru, precīzu atbildi dažu sekunžu laikā.
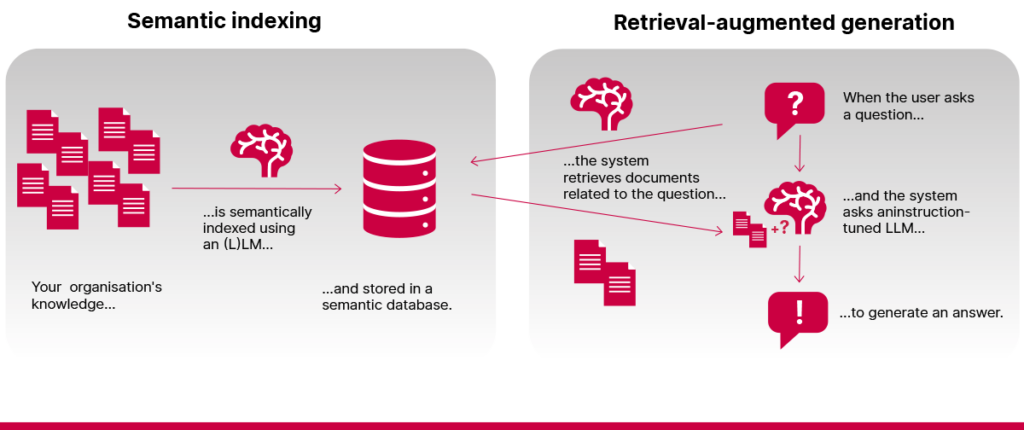
Ko var paveikt vienkāršs RAG risinājums?
Vienkārša (jeb “naiva”) RAG sistēma var labi izpildīt divas pamatfunkcijas.
1️⃣ Atrast dokumentos tiešas atbildes. Ja kaut kur indeksētajos dokumentos ir atrodama precīza atbilde, RAG sistēma var to atrast un sniegt jums. Tas bieži ir efektīvāk par klasisko meklēšanu, jo sistēma var saprast jautājumu pat tad, ja tas ir formulēts citādi nekā dokumenta saturs.
2️⃣ Sniegt informācijas kopsavilkumu. RAG modeļi var apkopot atrastajos dokumentos esošo informāciju, pārvēršot lielu teksta apjomu īsākās, vieglāk lasāmās atbildēs.

Kādos gadījumos ar vienkāršu RAG sistēmu nepietiek?
Neraugoties uz ieguvumiem, vienkārši RAG risinājumi saskaras arī ar grūtībām. Lūk, daži piemēri.
- Zemas kvalitātes dati
Datu kvalitāte ir bieži apspriests būtisks aspekts, runājot par RAG ierobežojumiem un izaicinājumiem — un tam ir pamats. Zemas kvalitātes dati noved pie zemas kvalitātes atbildēm. Ja dokumenti ir novecojuši, tajos ir faktu kļūdas, tie ir slikti strukturēti vai nepilnīgi, sistēma var ģenerēt neatbilstošas, maldinošas vai gluži vienkārši nepareizas atbildes. Tomēr tā ir tikai aisberga redzamā daļa.
- Vajadzība izdarīt sarežģītus spriedumus vai aprēķinus
RAG sistēmas nav kalkulatori vai relāciju datubāzes. Tām ir grūtības izpildīt uzdevumus, kas ietver matemātiku un skaitīšanu. Piemēram, uz jautājumu, cik līgumu uzņēmumam ir ar konkrētu klientu, šī sistēma bieži nevar atbildēt, ja katrs līgums tiek glabāts kā atsevišķs dokuments.
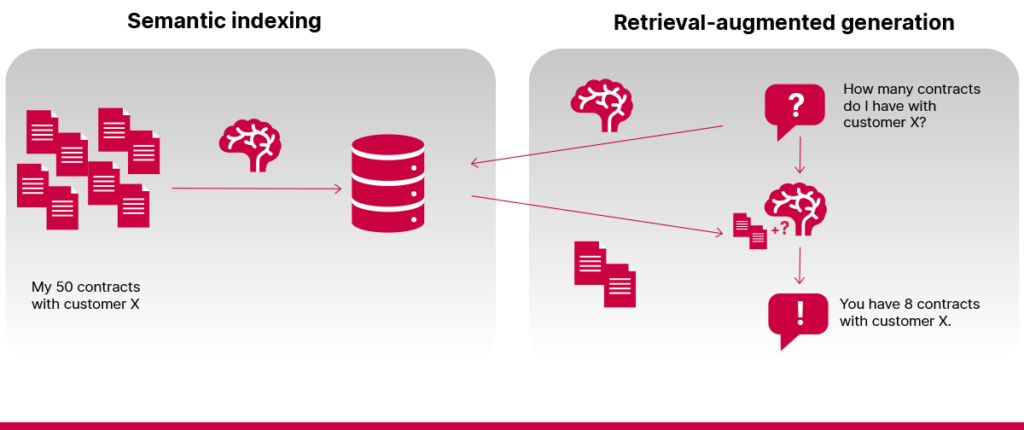
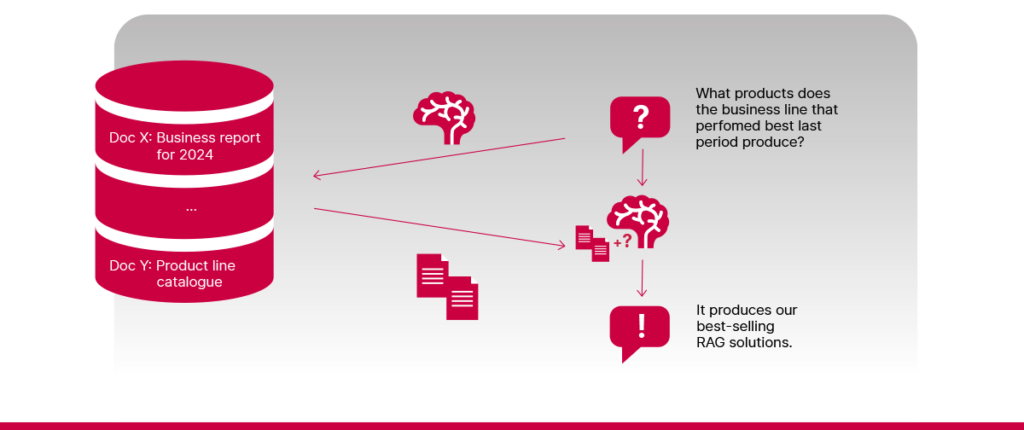
- Vajadzība pēc pakāpeniska spriešanas procesa
Daži jautājumi liek sistēmai domāt vairākos posmos. Piemēram, iztēlojieties, ka jūsu zināšanu bāzē ir divi dokumenti: vienā ir izklāstīts, kā dažādām uzņēmuma struktūrvienībām ir veicies pēdējā pārskata periodā, savukārt otrs uzskaita, kādus produktus katra struktūrvienība ražo. Ja jūs jautājat “Kādus produktus ražo uzņēmuma struktūrvienība, kurai ir vislabākie rezultāti?”, sistēmai vispirms jāsaprot, kura struktūrvienība ir sasniegusi labākos rezultātus, un pēc tam jānoskaidro, ko tā ražo. Šādos gadījumos var nepietikt ar vienkāršu viena soļa izguves un atbildes ģenerēšanas procesu, īpaši, ja reālajā praksē jautājumi ir daudz sarežģītāki.
- Salikti jautājumi
Dažkārt vienā jautājumā var būt ietverts lūgums noskaidrot vairākas informācijas vienības, kas meklējamas vairākos atšķirīgos dokumentos. Vienkāršam RAG modelim, kuram ir pa spēkam veikt tikai vienu izguves ciklu, var neizdoties atrast visus atbilstošos dokumentus vienlaikus un sniegt atbildi, kas aptvertu visus lietotāja jautājumā minētos faktorus.
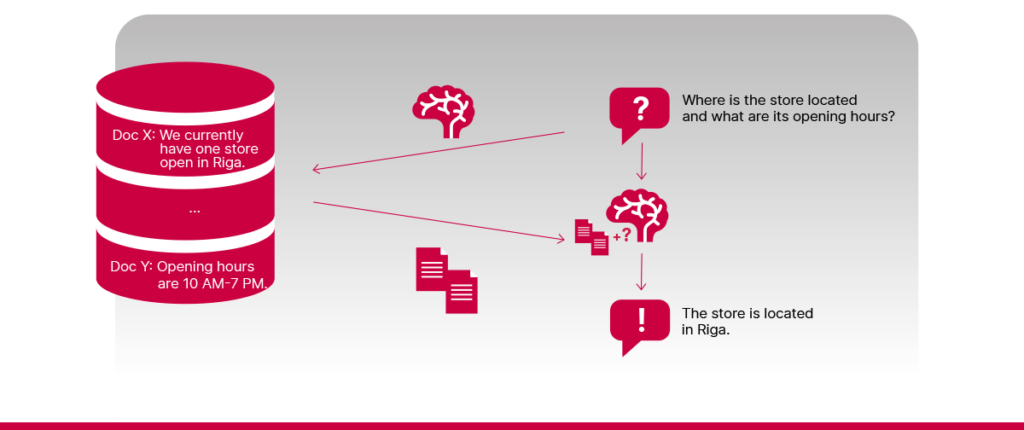
- Ierobežots konteksta apjoms
Visiem valodas modeļiem ir maksimālā ievades garuma ierobežojums, kas nozīmē, ka tie vienā pieprasījumā var apstrādāt tikai noteiktu teksta apjomu. Ja šis ierobežojums tiek pārsniegts, pārējais konteksts tiek atmests. Piemēram, ja lūdzat sniegt gara dokumenta kopsavilkumu vai uzdodat jautājumu, kuram ir nepieciešama informācija no pārāk daudziem dokumentiem vienlaikus, sistēma var palaist garām būtiskas detaļas — vienkārši tāpēc, ka sistēma “neredz” visu, kas nepieciešams pareizas atbildes ģenerēšanai.
- Lietotāja profila izpratne kontekstā
Vienkārša RAG sistēma nezina neko par lietotāju un viņa lomu. Ja datubāzē ir pretrunīgi dokumenti, kas ir paredzēti dažādām lietotāju grupām, sistēmai var būt grūtības izvēlēties pareizo kontekstu bez papildu informācijas no lietotāja. Piemēram, iztēlojieties, ka RAG sistēma ir indeksējusi divus dokumentus: vienu, paredzētu juridiskām personām, kurā minēts, ka sadarbības veikšanai ir nepieciešams līgums, un otru, paredzētu fiziskām personām, kurā norādīts, ka līgums nav nepieciešams. Ja jautāsiet, vai jums jāslēdz līgums, bet nenorādīsiet, ka esat juridiska vai fiziska persona, RAG sistēma var sniegt nepareizu atbildi.

Protams, ir gadījumi, kad RAG sistēma veiksmīgas sakritības dēļ atrod visus jautājumam atbilstošos dokumentus arī tad, kad ir nepieciešama pakāpeniska spriešana. Dažkārt informācija dokumentos jau ir sniegta apkopotā veidā un aprēķini nav vajadzīgi. Taču tie ir izņēmumi, nevis likumsakarība. Vienkāršs (“naivs”) RAG risinājums nevar apstrādāt sarežģītus jautājumus vai dažādu organizāciju specifiskās vajadzības.
Vienkāršas RAG sistēmas ierobežojumu risināšana
Šo ierobežojumu pārvarēšanai ir nepieciešama sarežģītāka pieeja — tāda, kas sniedzas tālāk par viena soļa semantisko meklēšanu un atbildes ģenerēšanu. Te ir vieta aģentu izguves papildinātai ģenerēšanai.
Aģentu RAG izmanto autonomus aģentus, no kuriem katrs ir veidots tā, lai prastu apstrādāt kāda konkrēta veida uzdevumus un atbildēt uz sarežģītiem jautājumiem. Piemēram, vieni aģenti var veidot garu dokumentu kopsavilkumus, citi var veikt aprēķinus, vēl citi var izgūt aktuālu informāciju no ārējiem API un tā tālāk. Šie aģenti var pildīt uzdevumus, kuri sagādā grūtības vienkāršai RAG sistēmai. Daži aģentu izmantošanas piemēri:
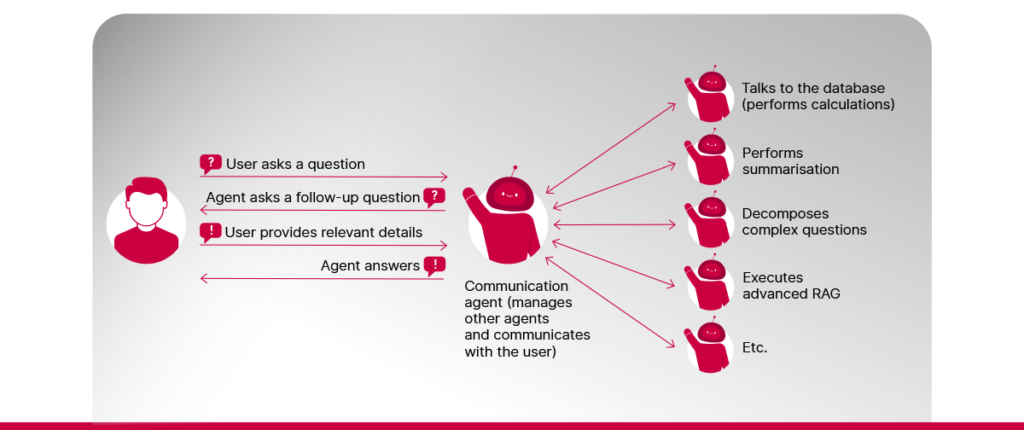
1️⃣ Sarežģītu jautājumu sadalīšana. Sarežģītu daudzdaļīgu jautājumu sadalīšana mazākos uztveramos jautājumos palīdz vieglāk izgūt atbilstošus dokumentus un ģenerēt atbildes, kas aptver visus saliktu jautājumu aspektus.
2️⃣ Informācijas iegūšana no lietotāja. Ja lietotāja vaicājums nav skaidrs vai tajā trūkst kādu datu, aģenti var iesaistīties un uzdot papildjautājumus, lai iegūtu nepieciešamo informāciju.
3️⃣ API izpilde. Ne visa informācija var būt pieejama organizācijas dokumentos. Daļa datu, iespējams, glabājas iekšējās sistēmās, kurām var piekļūt ar API. RAG sistēmas funkcionalitāti var ievērojami paplašināt, atļaujot tai piekļūt citās sistēmās glabātiem datiem.
4️⃣ Informācijas meklēšana datubāzē. Ja organizācija glabā datus datubāzēs, LVM var “pārtulkot” lietotāju jautājumus datubāzes vaicājumos. RAG aģentam var uzdot izpildīt šos vaicājumus un savākt atbildei nepieciešamo informāciju. Ja organizācijai ir daudz līdzīgas uzbūves dokumentu (piem., līgumi, projektu dokumentācija u.c.), LVM var palīdzēt arī izgūt metadatus no šiem dokumentiem. Tas atvieglo datubāžu veidošanu gadījumos, kad lietotāji vēlas uzdot jautājumus, kuru atbildēšanai jāveic aprēķini.
5️⃣ Atbilžu sniegšana uz jautājumiem, izmantojot uzlabotu RAG. RAG pati ir uzdevums, kuru var veikt LVM aģents. Sniedzoties tālāk par vienkāršas RAG sistēmas iespējām, uzlabota RAG piedāvā dažādas metodes, kuru mērķis ir pilnveidot sistēmas iespējas izgūt atbilstošus dokumentus pirms atbildes ģenerēšanas, piemēram:
- Hibrīdi semantiskā meklēšana. Efektīvas metodes piemērs ir hibrīdā meklēšana, kas apvieno semantisko meklēšanu ar klasisko meklēšanu, kurā tiek izmantoti atslēgvārdi. Tas palīdz izgūt dokumentus, kas atbilst gan tēmai, gan leksikai. Tas ir īpaši lietderīgi, apstrādājot daudzveidīgas dokumentu kopas.
- Hipotētisko dokumentu ģenerēšana. Jautājumi dabiski atšķiras no dokumentiem, kuri RAG sistēmai ir jāatrod. Piemēram, jautājumi var būt īsi un kodolīgi, savukārt dokumenti — gari un detalizēti. Jautājumi bieži sastāv no viena teikuma, kas beidzas ar jautājuma zīmi, savukārt dokumentos var būt simtiem teikumu, kuri reti beidzas ar jautājuma zīmēm. Šis atšķirīgums bieži ir semantiskās meklēšanas kļūdu cēlonis. Viens paņēmiens, kā panākt lielāku līdzību, ir uz lietotāja jautājumu vispirms ģenerēt hipotētisku dokumentu (vai atbildi) bez konteksta. Pēc tam sistēma izmanto šo ģenerēto tekstu, lai meklētu datubāzē līdzīgus dokumentus, bieži vien ar labākiem rezultātiem.
- Jautājumu un tēžu ģenerēšana dokumentiem. Tas ir vēl viens paņēmiens, kā samazināt semantisko atšķirību starp jautājumiem un dokumentiem. Kad lietotāji augšupielādē dokumentus, mēs varam lūgt LVM ģenerēt iespējamus jautājumus vai sarakstu ar kodolīgiem faktiskiem apgalvojumiem (tēzēm) par katru augšupielādēto dokumentu. Mēs indeksējam šos jautājumus un tēzes semantiskā datubāzē kopā ar saiti uz oriģinālo dokumentu. Kad lietotājs uzdod jautājumu, sistēma to salīdzina ar šiem īsākajiem, jautājumiem līdzīgajiem ierakstiem, kas atvieglo visatbilstošāko dokumentu atrašanu.
- Izgūto dokumentu pārkārtošana. Ne visi izgūtie dokumenti ir vienlīdz lietderīgi vai atbilstoši lietotāja jautājumam. Tie var būt satura ziņā līdzīgi, bet atbilstība nav garantēta. Lai labotu šo nepilnību, pārkārtošanas LVM var pārskatīt izgūtos dokumentus, novērtēt atbilstību un attiecīgi tos sarindot. Tas palīdz nodrošināt, ka ģeneratīvais LVM formulē atbildi, strādājot ar visatbilstošāko kontekstu.
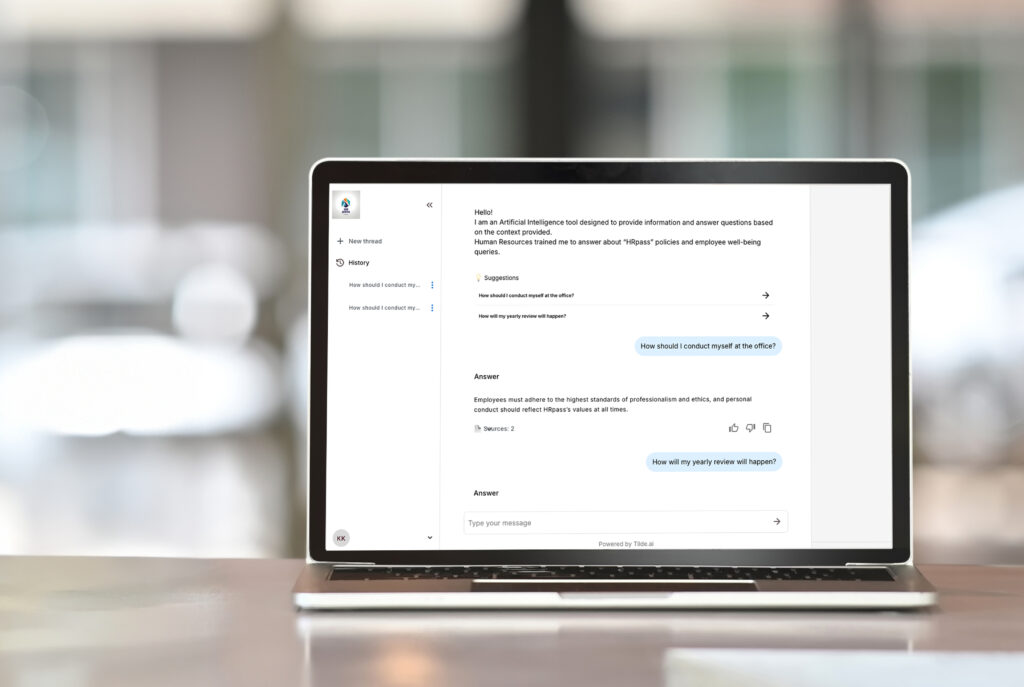
Tilde Enterprise Assistant ir jaudīgs aģentu RAG risinājuma piemērs, kas ir izstrādāts, lai pielāgotos jebkuras organizācijas konkrētajām vajadzībām. Galvenās funkcijas ir, piemēram:
- hibrīdi semantiskā meklēšana ar integrētu datu ģenerēšanu, izmantojot LVM;
- saliktu jautājumu sadalīšana precīzāku un pilnīgāku atbilžu iegūšanai;
- automātiska dokumentu metadatu izgūšana un datubāžu aizpildīšana;
- dialogos balstīti scenāriji ārējo API izpildei vai informācijas vākšanai tieši no lietotājiem;
- elastīga modeļa izvēle, kas viegli ļauj mainīt indeksēšanas VM un ģeneratīvos LVM;
- plaši pielāgojamas darbplūsmas, izstrādātas dažādu uzņēmumu lietošanas gadījumiem.
Valodas modeļu loma RAG sistēmās
Pēc būtības RAG sistēmas izmanto trīs dažādu veidu valodas modeļus: indeksēšanas (jeb kartēšanas) valodas modeli, pārkārtošanas valodas modeli un ģeneratīvo LVM. Pašreizējie modernākie atvērtie un slēgtie LVM ir apmācīti, izmantojot datus, kuros dominē angļu valoda, tādēļ rezultāti nav tik akurāti valodām, kuras apmācības datos ir mazāk pārstāvētas. Valodas ar mazāku runātāju skaitu, tostarp latviešu, lietuviešu un igauņu valoda, bieži saņem mazāk uzmanības, tādēļ LVM var pieļaut gramatikas kļūdas, sniegt nepareizas kulturālas interpretācijas un atbildēs neņemt vērā vietējo informāciju.
Lai mazinātu lingvistiskos un kulturālos ierobežojumus, ko vērojam esošo lielo valodas modeļu darbībā, Tilde izstrādā TildeLM — atvērtu valodas pamatmodeli, pielāgotu Eiropas valodām. Mūsu prioritāte ir baltu, somu un slāvu valodas. Mūsu redzējums ir vienlīdzīga mūsu prioritāro valodu pārstāvniecība, kas nodrošina, ka modelis apgūst vietējās īpatnības, gramatikas un kultūras nianses — to, ko angļu valodā balstīti modeļi bieži palaiž garām. TildeLM modeļa apmācība sākās 2024. gada martā, izmantojot LUMI superdatoru Somijā. Pēc pabeigšanas modelis tiks pilnveidots tālākiem uzdevumiem, piemēram, mašīntulkošanai, jautājumu atbildēšanai kontekstā (kā tā tiek veikta RAG sistēmās) un citiem.
Secinājums
Lai gan vienkāršas RAG sistēmas var izpildīt skaidrus un vienkāršus vaicājumus, tām bieži ir grūtības, saskaroties ar reālās pasaules sarežģīto dabu — pakāpenisku spriešanas procesu, neviennozīmīgiem jautājumiem vai uzdevumiem, kas prasa ārēju sistēmu izmantošanu. Organizācijām, kuras meklē patiesi vērtīgu risinājumu, nepārprotami labākā izvēle ir aģentu RAG sistēma.
Tāds ir Tilde Enterprise Assistant redzējums: aģentos balstīta RAG sistēma, kas izstrādāta, lai sniegtu atbalstu sarežģītu uzdevumu veikšanā, pielāgotos dažādām darbplūsmām un kļūtu par tiešām vērtīgu palīgu.
Bet izcils MI nebeidzas ar funkciju izpildi — tam ir arī jāsaprot lietotāju valoda un kultūra. Pēc apmācības pabeigšanas TildeLM būs pilnveidots tieši darbam ar RAG, kas ļaus sistēmai labāk izprast vietējo gramatiku, terminoloģiju un kontekstu — tā būs ne tikai gudra, bet patiesi daudzvalodīga sistēma.


