Daugiau nei paprastas informacijos paieška papildytas generavimas
„Tilde“ komanda 2025 m. gegužės 14 d.
Kas yra informacijos paieška papildytas generavimas (RAG)?
Informacijos paieška papildytas generavimas (angl. Retrieval-Augmented Generation, RAG) tapo veiksmingu metodu, leidžiančiu apmokyti didžiuosius kalbos modelius (LLM) pagal konkrečioms sritims pritaikytą turinį. Iš esmės RAG sistemos leidžia naudotojams indeksuoti dokumentų rinkinį ir natūraliąja kalba užduoti klausimų, susijusius su tų dokumentų turiniu. Sistema atsako į užklausą pirmiausia atrinkdama dokumentus, kurie labiausiai atitinka užklausą, o tada, remdamasis šia informacija, LLM sugeneruoja atsakymą. Principas paprastas: naudotojai gali pateikti klausimų apie savo duomenis, tarsi kalbėtųsi su ekspertu, o sistema pateikia glaustus ir naudingus atsakymus.
Štai pavyzdys, kaip tai veikia. Įsivaizduokite, kad turite didžiulę krūvą įmonės dokumentų ir jums reikia rasti vieną ataskaitą, kurioje būtų nurodyti prieš penkerius metus perkamiausi produktai. Jums nereikia ieškoti patiems – tam turite išmanųjį asistentą, kuris suranda reikiamą ataskaitą, perskaito ją ir per kelias sekundes pateikia aiškų ir tikslų atsakymą.
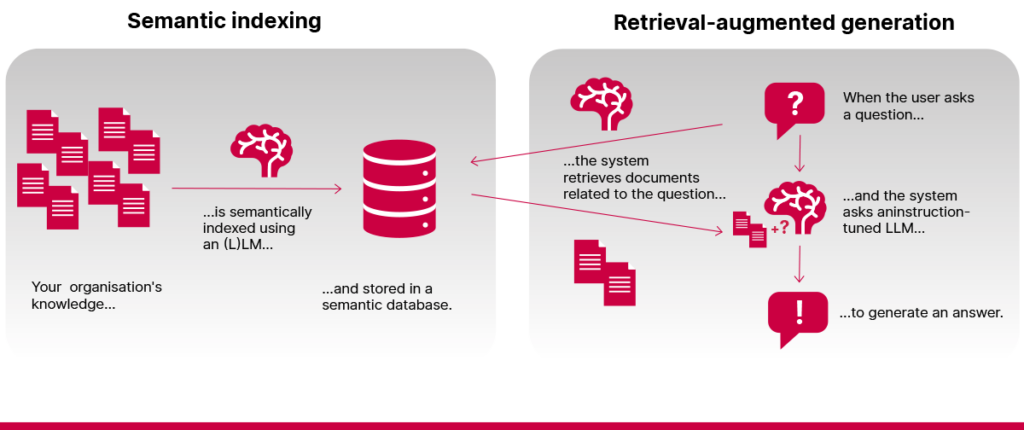
Ką gali paprastasis RAG sprendimas?
Paprastoji (arba nesudėtingoji) RAG sistema gali gerai atlikti dvi pagrindines funkcijas:
1️⃣ Dokumentuose rasti tiesioginius atsakymus. Jei tikslus atsakymas yra kur nors indeksuotuose dokumentuose, RAG sistema gali jį surasti ir jums pateikti. Dažnai ji veikia geriau nei tradicinė paieška, nes gali suprasti klausimą, net jei jis suformuluotas kitaip nei jūsų dokumentų turinys.
2️⃣ Apibendrinti informaciją. RAG modeliai gali apibendrinti rastus dokumentus ir didelius teksto kiekius paversti trumpesniais, lengviau skaitomais atsakymais.

Kada paprastasis RAG yra nepakankamas?
Nepaisant jų pranašumų, paprasti RAG sprendimai gali susidurti su daugybe iššūkių, pavyzdžiui:
- Prasta duomenų kokybė
Duomenų kokybė dažnai būna pagrindinis klausimas, kai kalbama apie RAG apribojimus ir iššūkius, ir ne veltui. Prastos kokybės duomenys lemia prastos kokybės atsakymus. Jei dokumentai pasenę, juose yra faktinių klaidų, jie prastos struktūros arba neišsamūs, sistema gali pateikti nereikšmingus, klaidinančius arba tiesiog neteisingus atsakymus. Tačiau tai tik ledkalnio viršūnė.
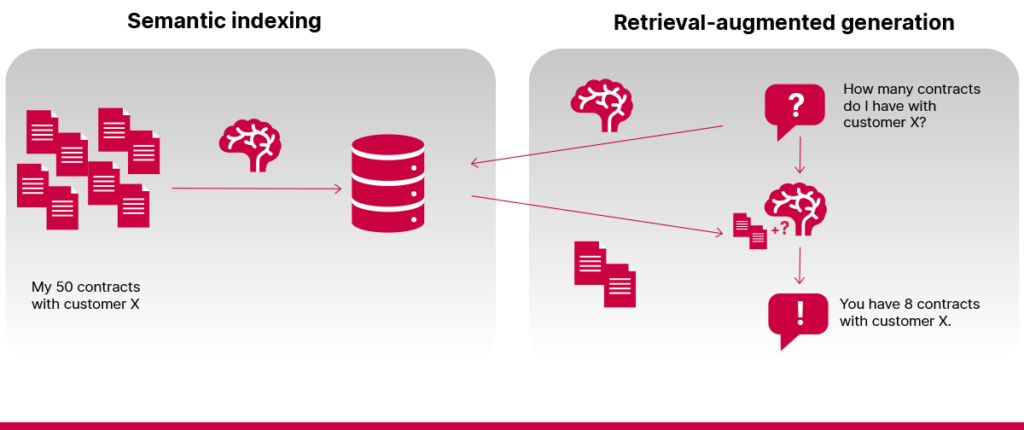
- Sudėtingų samprotavimų ar skaičiavimų poreikis
RAG sistemos nėra skaičiuotuvai ar sąryšinės duomenų bazės. Joms sunkiai sekasi atlikti matematines ir skaičiavimo užduotis. Pavyzdžiui, paklausus, kiek sutarčių įmonė yra sudariusi su konkrečiu klientu, sistema dažnai negali atsakyti, jei kiekviena sutartis saugoma kaip atskiras dokumentas.
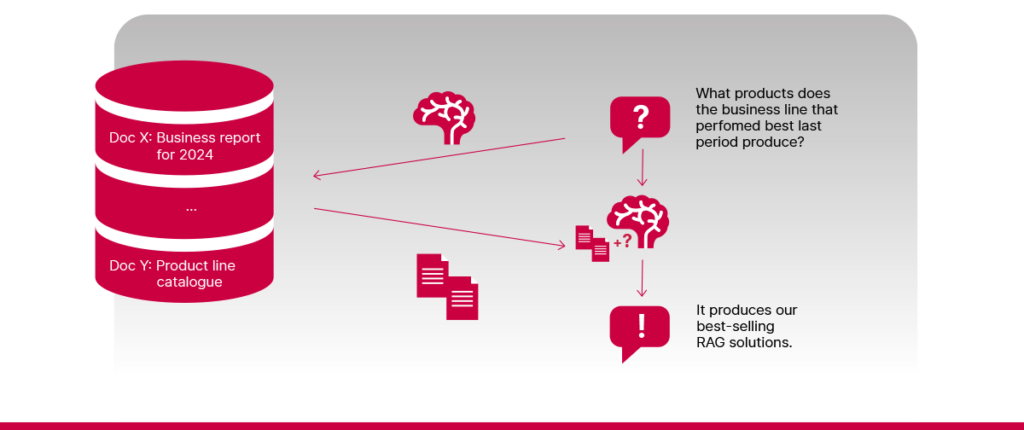
- Poreikis argumentuoti žingsnis po žingsnio
Norint atsakyti į kai kuriuos klausimus, reikia, kad sistema mąstytų etapais. Pavyzdžiui, įsivaizduokite, kad jūsų žinių bazėje yra du dokumentai – viename aiškinama, kaip skirtingoms verslo linijoms sekėsi praėjusį laikotarpį, o kitame vardijama, kokius produktus gamina kiekviena verslo linija. Jei klausiate: „Kokius gaminius gamina geriausius rezultatus pasiekusi verslo linija?“, sistema pirmiausia turi išsiaiškinti, kuri linija pasiekė geriausius rezultatus, o tada sužinoti, ką ji gamina. Tokiais atvejais gali nepakakti paprasto vieno žingsnio paieškos ir atsakymo sugeneravimo proceso, ypač kai realūs klausimai būna daug sudėtingesni.
- Sudėtiniai klausimai
Kartais viename klausime gali būti prašoma pateikti keletą informacijos vienetų, kurie pasiskirstę keliuose skirtinguose dokumentuose. Paprastasis RAG modelis, apsiribojantis tik vienu paieškos etapu, gali nesugebėti vienu metu gauti visų svarbių dokumentų ir sugeneruoti atsakymo, kuris apimtų visus naudotojo klausimo aspektus.
- Ribota konteksto apimtis
Visi kalbos modeliai turi maksimalaus įvesties ilgio ribą, t. y. vienu metu gali apdoroti tik tam tikrą teksto kiekį. Jei ši riba viršijama, likęs kontekstas numetamas. Pavyzdžiui, jei paprašysite apibendrinti ilgą dokumentą arba užduosite klausimą, kuriam reikia informacijos iš pernelyg daug dokumentų vienu metu, sistema gali praleisti svarbius duomenis paprasčiausiai todėl, kad modelis „nemato“ visko, ko reikia tiksliam atsakymui sugeneruoti.
- Kontekstinis naudotojo profilio supratimas
Paprastoji RAG sistema nieko nežino apie naudotoją ar jo vaidmenį. Jei duomenų bazėje yra vienas kitam prieštaraujančių dokumentų – vieni skirti vienai naudotojų grupei, kiti – kitai, sistemai gali būti sunku pasirinkti tinkamą kontekstą, jei naudotojas nepateiks daugiau informacijos. Įsivaizduokite, kad RAG sistemoje indeksuoti du dokumentai – vienas skirtas juridiniams asmenims, kuriame teigiama, kad norint užsiimti verslu reikia pasirašyti sutartį, o kitas – fiziniams asmenims, kuriame teigiama, kad sutartis nereikalinga. Jei klausiate, ar jums reikia sutarties, bet nenurodote, ar esate juridinis, ar fizinis asmuo, RAG sistema gali pateikti neteisingą atsakymą.

Akivaizdu, kad pasitaiko atvejų, kai RAG sistemai pasiseka ir ji suranda visus reikalingus dokumentus, susijusius su klausimu, kurį reikia pagrįsti žingsnis po žingsnio. Kartais informacija dokumentuose jau būna pateikta apibendrinta, todėl skaičiavimų atlikti nereikia. Tačiau tai yra išimtys, o ne taisyklė. Paprastoji (nesudėtingoji) RAG sąranka nepajėgi spręsti sudėtingų klausimų ar tenkinti konkrečių skirtingų organizacijų poreikių.
Daugiau nei paprastas RAG
Norint įveikti šiuos apribojimus, reikia pažangesnio požiūrio, kuris neapsiribotų vieninteliu semantinės paieškos ir atsakymų generavimo etapu. Tam pasitelkiamas agentinis informacijos paieška papildytas generavimas.
Agentinis RAG naudoja autonominius agentus, kurių kiekvienas sukurtas tam tikro tipo užduotims, reikalingoms atsakyti į sudėtingus klausimus. Pavyzdžiui, kai kurie agentai gali apibendrinti ilgus dokumentus, kiti – atlikti skaičiavimus, treti – gauti naujausią informaciją iš išorinių API ir t. t. Šie agentai gali imtis užduočių, su kuriomis paprastosios RAG sistemos sunkiai susidoroja. Pavyzdžiui, jie gali būti naudojami:
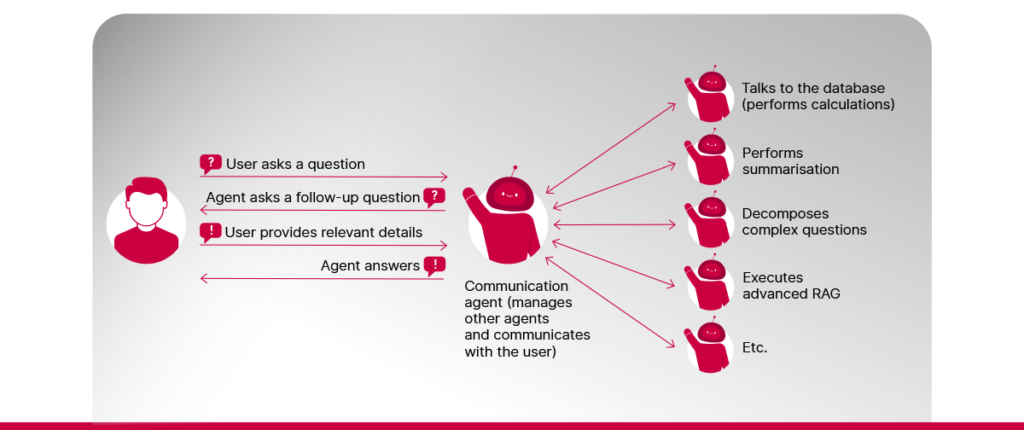
1️⃣ Sudėtiniams klausimams suskaidyti. Sudėtingus, iš kelių dalių sudarytus klausimus suskaidžius į mažesnius ir paprasčiau apdorojamus klausimus, lengviau gauti daugiau aktualių dokumentų ir sugeneruoti atsakymus, apimančius visus sudėtinių klausimų aspektus.
2️⃣ Informacijai iš naudotojo surinkti. Kai naudotojo užklausa neaiški arba trūksta informacijos, agentai gali užduoti papildomų klausimų ir surinkti reikiamą informaciją.
3️⃣ Vykdyti API. Organizacijos dokumentuose gali būti pateikta ne visa informacija. Kai kurie duomenys gali būti saugomi vidinėse sistemose, prie kurių prieiga suteikiama per API. RAG sistemos funkcionalumą galima gerokai išplėsti suteikiant jai prieigą prie kitose sistemose saugomų duomenų.
4️⃣ Informacijos paieška duomenų bazėje. Jei organizacija savo duomenis saugo duomenų bazėse, LLM gali „išversti“ naudotojų klausimus į duomenų bazės užklausas. Tuomet RAG agentui gali būti pavesta vykdyti šias užklausas ir rinkti informaciją atsakymui gauti. Jei organizacija turi panašios struktūros dokumentų (pvz., sutarčių, projektų dokumentų ir pan.), LLM taip pat gali padėti iš dokumentų išgauti metaduomenis. Tai palengvina duomenų bazių kūrimą tais atvejais, kai naudotojai nori užduoti klausimų, kuriems reikia atlikti skaičiavimus.
5️⃣ Atsakyti į klausimus naudojant pažangų RAG. Pats RAG yra užduotis, kurią gali atlikti LLM agentas. Išplėstiniame RAG taikomi įvairūs metodai, kuriais siekiama pagerinti būdą, kaip sistema suranda atitinkamus dokumentus prieš sugeneruodama atsakymą, pavyzdžiui:
- Hibridinė semantinė paieška. Vienas iš veiksmingų metodų yra hibridinė paieška, kai semantinė paieška derinama su tradicine paieška pagal raktinius žodžius. Tai padeda gauti dokumentus, kurie yra aktualūs ir pagal temą, ir pagal leksiką. Tai ypač naudinga, kai dokumentų rinkinys yra įvairus.
- Hipotetinio dokumento generavimas. Natūralu, kad klausimai skiriasi nuo dokumentų, kuriuos norime, kad rastų RAG sistema. Pavyzdžiui, klausimai yra glausti ir trumpi, o dokumentai – ilgi ir išsamūs. Klausimus dažnai sudaro tik vienas sakinys su klaustuku gale, o dokumentus gali sudaryti šimtai ar daugiau sakinių, kurie retai baigiasi klaustuku. Šis skirtumas dažnai ir būna semantinės paieškos nesėkmės priežastis. Vienas iš panašumo didinimo būdų – pirmiausia sukurti hipotetinį dokumentą (arba atsakymą) į naudotojo klausimą, nenaudojant jokio konteksto. Tada sistema naudoja šį sugeneruotą tekstą panašių dokumentų paieškai duomenų bazėje, o rezultatai dažnai būna geresni.
- Klausimų ir tezių generavimas dokumentams. Tai dar vienas būdas, kaip sumažinti semantinį atotrūkį tarp klausimų ir dokumentų. Kai naudotojai įkelia dokumentus, galime paprašyti LLM sugeneruoti galimus klausimus arba glaustų faktinių teiginių (tezių) sąrašą kiekvienam įkeltam dokumentui. Šiuos klausimus ir tezes indeksuojame semantinėje duomenų bazėje kartu su nuoroda į originalų dokumentą. Kai naudotojas užduoda klausimą, sistema palygina jį su šiais trumpesniais, į klausimus panašiais įrašais, todėl lengviau rasti aktualiausius dokumentus.
- Gautų dokumentų perrinkimas. Ne visi gauti dokumentai yra vienodai naudingi ar aktualūs pagal naudotojo klausimą. Jų turinys gali būti panašus, tačiau aktualumas negarantuojamas. Norint tai ištaisyti, perrinkimo LLM gali peržiūrėti gautus dokumentus, įvertinti jų aktualumą ir atitinkamai juos surikiuoti. Tai padeda užtikrinti, kad generatyvinis LLM, formuluodamas atsakymą, dirbtų su aktualiausiu kontekstu.
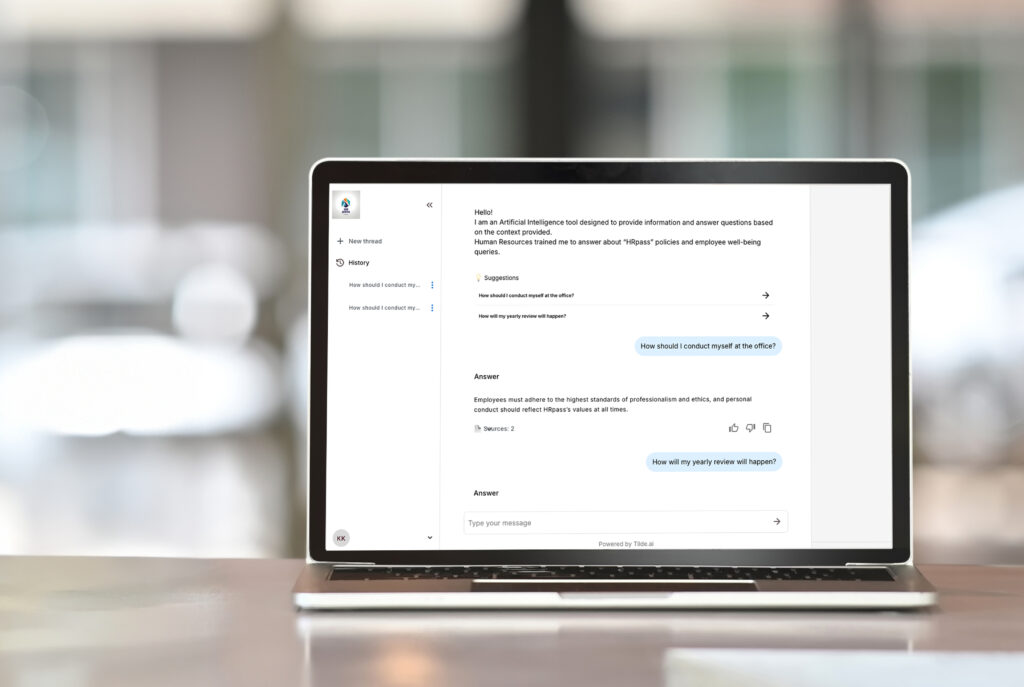
„Tilde Enterprise Assistant“ yra efektyvus agentinio RAG sprendimo pavyzdys, sukurtas taip, kad jį būtų galima pritaikyti prie konkrečių bet kurios organizacijos poreikių. Pagrindinės funkcijos:
- hibridinė semantinė paieška su integruotu duomenų generavimu naudojant LLM;
- sudėtinių klausimų skaidymas, siekiant tikslesnių ir išsamesnių atsakymų;
- automatinis metaduomenų išgavimas iš dokumentų ir duomenų bazių pildymas;
- dialogu pagrįsti scenarijai, skirti išorinėms API vykdyti arba informacijai tiesiogiai iš naudotojų rinkti;
- lankstus modelio pasirinkimas, leidžiantis lengvai perjungti indeksuojančius LM ir generatyvinius LLM;
- darbo eigos, pritaikomos įvairiems įmonės naudojimo atvejams.
Kalbos modelių vaidmuo RAG sistemose
Apskritai RAG sistemose naudojami trijų skirtingų tipų kalbos modeliai: indeksavimo (arba įterpimo) kalbos modelis, perrinkimo kalbos modelis ir generatyvinis LLM. Dabartiniai moderniausi atvirieji ir uždarieji LLM yra daugiausia orientuoti į anglų kalbą, todėl kalbų, kurioms mokymo duomenyse yra nepakankamai atstovaujama, rezultatai nėra tokie tikslūs. Mažesnėms kalboms, pavyzdžiui, latvių, lietuvių ar estų, dažnai skiriama mažiau dėmesio, todėl LLM atsakymuose gali pasitaikyti negramatiškų išvesčių, kultūrinių klaidų ar vietinių žinių trūkumo.
Siekdama pašalinti esamų didžiųjų kalbų modelių lingvistines ir kultūrines spragas, „Tilde“ kuria „TildeLM“ – Europos kalboms pritaikytą atvirąjį pamatinį LLM. Daugiausia dėmesio skiriame baltų, suomių ir slavų kalboms. Siekiame, kad kiekviena iš mums aktualių kalbų būtų vienodai atstovaujama, ir taip užtikrinti, kad modelis išmoktų vietines ypatybes, gramatiką ir kultūrinius niuansus – tai, ko dažnai pasigendama modeliuose, orientuotuose į anglų kalbą. „TildeLM“ mokymas pradėtas Suomijoje esančiame LUMI superkompiuteryje 2024 m. kovo mėn. Parengtas modelis bus pritaikytas tolesnėms užduotims, pavyzdžiui, mašininiam vertimui, kontekstiniam atsakymui į klausimus (kaip naudojama RAG sistemose) ir kt.
Išvada
Nors paprastosios RAG sistemos gali apdoroti paprastas užklausas, jos dažnai nepasiteisina, kai susiduriama su realaus pasaulio sudėtingumu – kelių etapų samprotavimais, dviprasmiškais klausimais arba užduotimis, kurioms reikia sąveikauti su išorinėmis sistemomis. Organizacijoms, ieškančioms tikrai pridėtinę vertę kuriančių sprendimų, agentinis RAG yra akivaizdus pasirinkimas.
Tokia yra „Tilde Enterprise Assistant“ vizija: agentais pagrįsta RAG sistema, sukurta sudėtingoms užduotims atlikti, prisitaikyti prie individualių darbo eigos procesų ir teikti realią vertę.
Tačiau puikus dirbtinis intelektas neapsiriboja vien funkcionalumu – jis taip pat turi suprasti naudotojų kalbą ir kultūrą. Išmokytas „TildeLM“ bus pritaikytas specialiai RAG, kad sistema galėtų geriau suprasti vietos gramatiką, terminiją ir kontekstą, todėl ji taps ne tik išmani, bet ir tikrai daugiakalbė.


