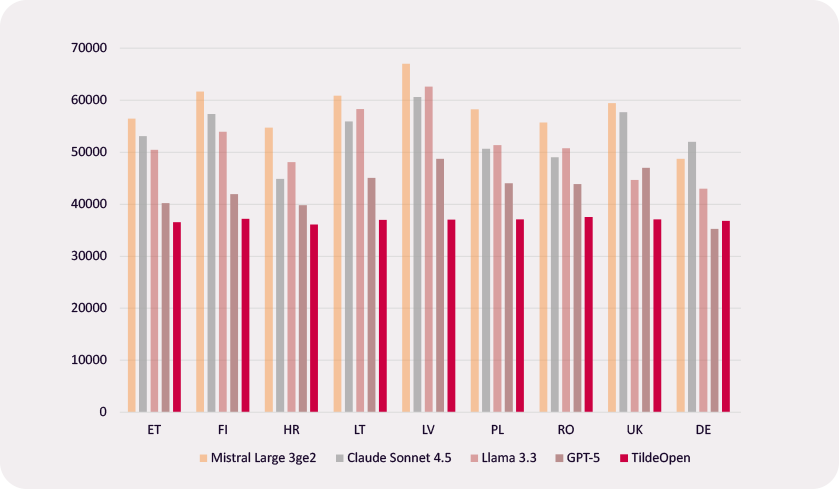
Dėl specialiai jiems sukurto tokenizatoriaus ir architektūros tildeopen daug morfologijos turtingų Europos kalbų vartojimo efektyvumas yra didesnis. Palyginti su Lama-3, jis yra 41% veiksmingesnis latvių kalba, 37% – lietuvių kalba, 31% inFinnish, 28 – estų% ir lenkų kalbomis, taip pat viršija GPT ir Mistral modelius. Tai lemia greitesnį teksto generavimą vietiniuose diegimuose ir atitinkamai mažesnes to paties kiekio duomenų eksploatavimo išlaidas. Peržiūrėti visus sąlyginio etalono rezultatus.
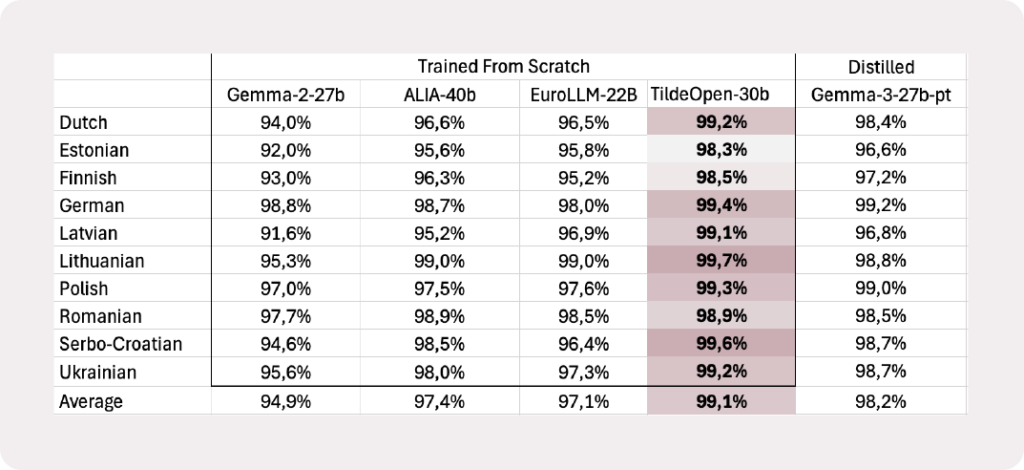
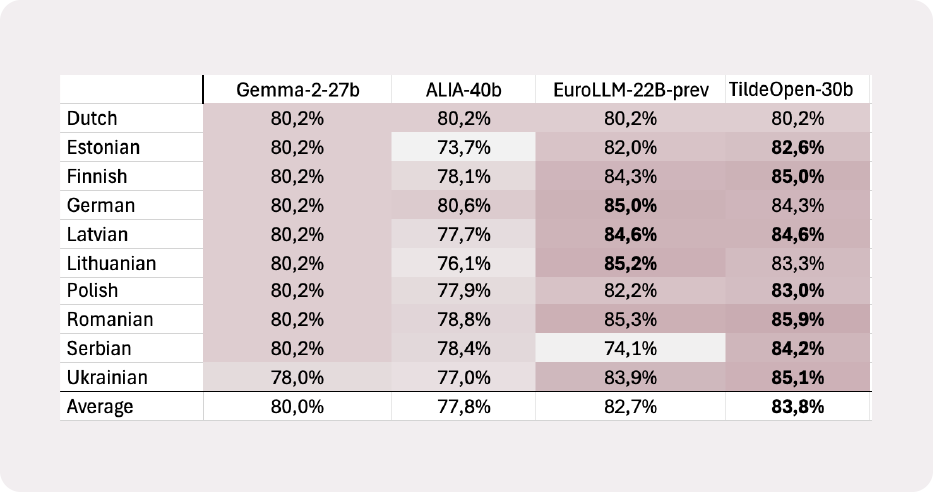
Tildeopen-30B pasiekia naujausią Belebele skaitymo supratimo kriterijaus rezultatą, kurio vidutinis tikslumas yra 84,7%. Šis modelis yra pranašesnis už kitus vietoje diegiamus modelius, pvz., Gemma-27B, ALIA-40B ir EuroLLM-22B. Peržiūrėti visus sąlyginio etalono rezultatus.