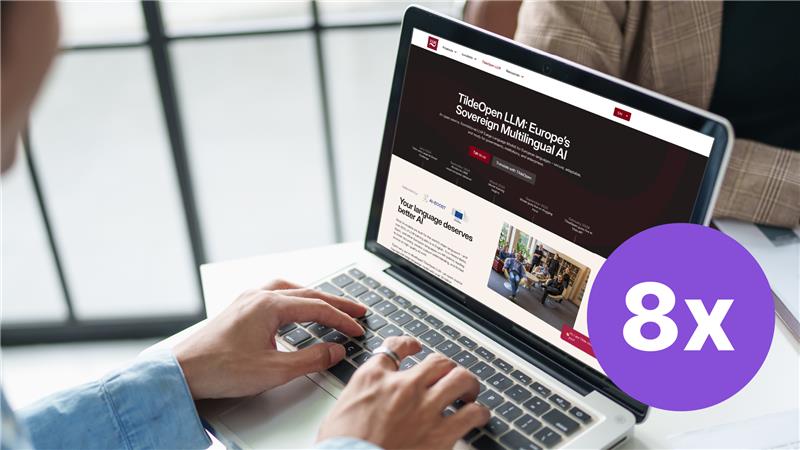
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) has become a powerful method for grounding large language models (LLMs) in content tailored to specific domains. In essence, RAG systems allow users to index a body of documents and ask questions concerning the content of those documents in natural language. The system responds by first retrieving documents that are most relevant to the query and then having an LLM generate an answer based on that information. The promise is straightforward: users can ask questions about their own data as if talking to an expert, and the system provides concise, helpful responses.
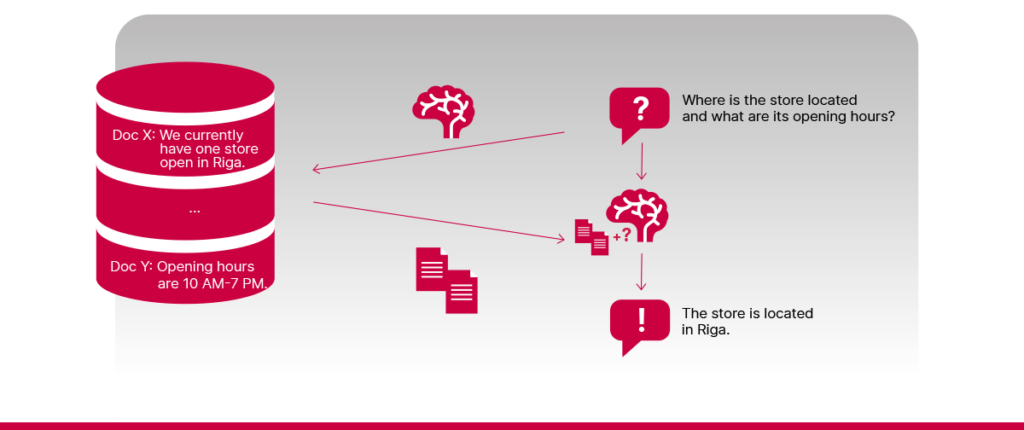
Here’s an example of how it works. Imagine you have a huge pile of company documents, and you need to find the one report that lists your top-selling products from five years ago. Instead of searching through everything yourself, you have a smart assistant who finds the right report, reads it and gives you a clear, accurate answer in seconds.
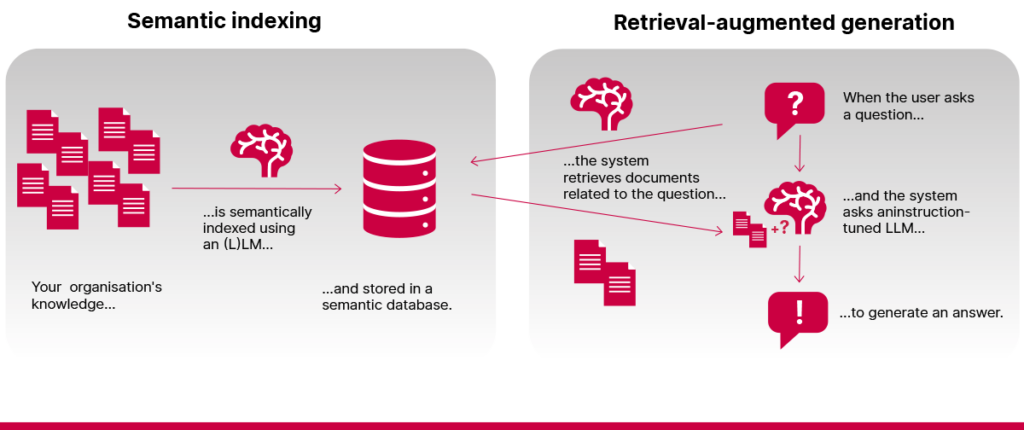
What can a simple RAG solution do?
A simple (or naive) RAG system can perform two main functions well:
1️⃣ Find direct answers in documents. If the exact answer exists somewhere in the indexed documents, a RAG system can find it and retrieve it for you. It often works better than a traditional search, as it can understand the question even if it’s phrased differently from the content of your documents.
2️⃣ Summarise information. RAG models can summarise the documents they find, turning large amounts of text into shorter, easier-to-read responses.

When does a simple RAG fall short?
Despite its appeal, simple RAG solutions can encounter numerous challenges, for example:
-
- Poor data quality
Data quality is often a major talking point when it comes to the limitations and challenges of RAG – and for good reason. Poor-quality data leads to poor-quality answers. If documents are outdated, contain factual errors, are poorly structured, or are incomplete, the system can produce irrelevant, misleading, or simply wrong responses. However, this is just the tip of the iceberg.
-
- Need for complex reasoning or calculations
RAG systems aren’t calculators or relational databases. They struggle with tasks that require maths and counting. For example, asking how many contracts a company has with a specific customer is often beyond the system’s scope when each contract is stored as a separate document.
-
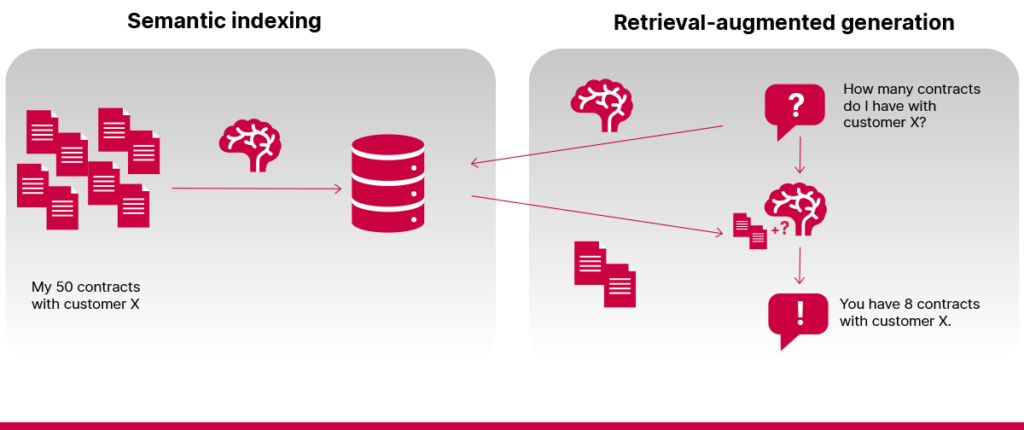
- Need for step-by-step reasoning
Some questions require the system to think in stages. For example, imagine that your knowledge base contains two documents – one explains how different business lines performed last period and the other lists which products each business line makes. If you ask, “What products does the best-performing business line produce?”, the system needs to first figure out which line performed best, and then find out what it makes. In cases like this, a simple one-step retrieval and answer generation process may not be enough – especially when real-world questions are much more complex.
-
- Composite questions
Sometimes, a single question might ask for multiple pieces of information that are spread across multiple different documents. A simple RAG model, limited to just one round of retrieval, may fail to retrieve all the relevant documents simultaneously and generate an answer that covers all aspects of the user’s question.
-
- Limited context length
All language models have a maximum input length threshold, meaning that they can only handle a certain amount of text at once. If that threshold is exceeded, the remaining context is dropped. For example, if you ask to summarise a long document, or ask a question that needs information from too many documents at once, the system might miss key details – simply because the model can’t “see” everything it needs to generate an accurate answer.
-
- Contextual understanding of the user’s profile
A simple RAG system doesn’t know anything about the user or their role. If there are conflicting documents in the database – some meant for one group of users and others for a different group – the system might struggle to choose the correct context without more information from the user. For example, imagine that the RAG system has indexed two documents – one intended for legal entities saying that they must have a contract signed to do business, and the other one for individuals, stating that no contract is needed. If you ask whether you need a contract but don’t specify that you’re a legal entity or an individual, the RAG system may provide the wrong answer.

Obviously, there are cases when a RAG system gets lucky and retrieves all the relevant documents for a question that requires step-by-step reasoning. Sometimes, the information in the documents is already provided in aggregated form, so calculations aren’t necessary. But these are exceptions, not the rule. The simple (naive) RAG setup isn’t capable of handling complex questions or the specific needs of different organisations.
Moving beyond the simple RAG
Overcoming these limitations calls for a more advanced approach – one that goes beyond a single step of semantic search and answer generation. This is where agentic retrieval-augmented generation comes in.
Agentic RAG uses autonomous agents, each designed to handle a specific type of task needed to answer complex questions. For example, some agents can summarise long documents, others can perform calculations, and some can retrieve up-to-date information from external APIs, and so on. These agents can take on tasks that simple RAG systems struggle with. For instance, they can be used to:
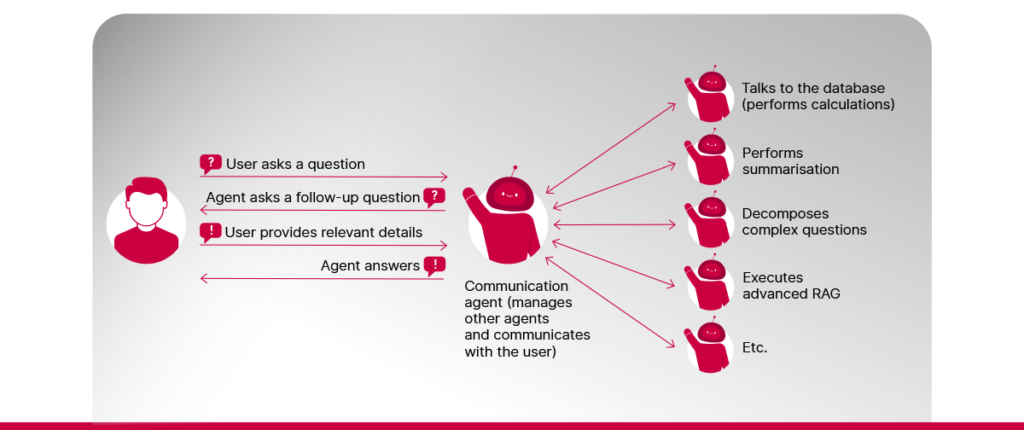
1️⃣ Decompose complex questions. Breaking down complex, multi-part questions into smaller, manageable questions makes it easier to retrieve more relevant documents and generate answers that cover all aspects of composite questions.
2️⃣ Gather information from the user. When a user’s request is unclear or missing details, agents can step in to ask follow-up questions and collect what’s needed.
3️⃣ Execute APIs. Not all information may be available in an organisation’s documents. Some data may be stored in internal systems accessed through APIs. A RAG system’s functionality can be substantially expanded by allowing it to access data stored in other systems.
4️⃣ Look up information in a database. If an organisation stores its data in databases, LLMs can “translate” user questions into database queries. A RAG agent can then be tasked to execute these queries and gather information for the answer. If an organisation has documents of similar structure (e.g., contracts, project documentation, etc.), LLMs can also help with extracting metadata from the documents. This makes it easier to build databases for cases when users want to ask questions that require calculations.
5️⃣ Answer questions using advanced RAG. RAG itself is a task that can be performed by an LLM agent. Beyond simple RAG, advanced RAG introduces various methods that aim to improve how well the system retrieves relevant documents before generating an answer, for example:
-
- Hybrid semantic search. One effective method is a hybrid search, which combines the semantic search with a traditional keyword-based search. This helps retrieve documents that are both topically and lexically relevant. This is especially useful when the document set is diverse.
-
- Hypothetical document generation. Questions are naturally dissimilar from documents that we want the RAG system to find. For instance, questions are concise and short, whereas documents are long and detailed. Questions often consist of just one sentence with a question mark at the end, whereas documents may consist of hundreds or more sentences that rarely end with question marks. This dissimilarity is often the reason why the semantic search fails. One method to increase similarity is to first generate a hypothetical document (or answer) to a user’s question without using any context. The system then uses this generated text to search for similar documents in the database, often leading to better results.
-
- Generation of questions and theses for documents. This is another method to reduce the semantic gap between questions and documents. When users upload documents, we can ask an LLM to generate potential questions or a list of concise factual statements (theses) for each uploaded document. We index these questions and theses in the semantic database together with a link to the original document. When a user asks a question, the system compares it to these shorter, question-like entries, making it easier to find the most relevant documents.
-
- Retrieved document re-ranking. Not all documents retrieved are equally useful or relevant to the user’s question. They may be similar content-wise, but relevance is not guaranteed. To fix this, a re-ranking LLM can review the retrieved documents, assess their relevance and sort them accordingly. This helps ensure that the generative LLM works with the most relevant context when forming its answer.
Tilde Enterprise Assistant is a powerful example of an agentic RAG solution, built to adapt to the specific needs of any organisation. Key features include:
-
- Hybrid semantic search with integrated data generation using LLMs;
-
- Decomposition of composite questions for more accurate and complete responses;
-
- Automatic meta-data extraction from documents and the population of databases;
-
- Dialogue-based scenarios for executing external APIs or collecting information directly from users;
-
- Flexible model selection, allowing easy switching between indexing LMs and generative LLMs;
-
- Highly customisable workflows tailored to varied enterprise use cases.
The role of language models in RAG
In general, RAG systems use three different types of language models: an indexing (or embedding) language model, a re-ranking language model, and a generative LLM. Current state-of-the-art open and closed LLMs are predominantly English-centric, resulting in less accurate results in languages that are underrepresented in the training data. Smaller languages, such as Latvian, Lithuanian or Estonian, often receive less attention and, therefore, LLMs can exhibit ungrammatical outputs, cultural misinterpretations, or a lack of local knowledge in responses.
To address the linguistic and cultural gaps in existing large language models, Tilde is developing TildeLM – an open foundational LLM tailored for European languages. Our focus languages are the Baltic, Finnic and Slavic languages. The vision is for each of our focus languages to be equally represented, ensuring that the model learns local characteristics, grammar and cultural nuances – something that English-centric models often miss. Training of TildeLM began in March 2024 on the LUMI supercomputer in Finland. Once ready, the model will be fine-tuned for downstream tasks, such as machine translation, in-context question answering (as used in RAG systems), and others.
Conclusion
While simple RAG systems can handle straightforward queries, they often fall short when faced with real-world complexity – multi-step reasoning, ambiguous questions, or tasks that require interacting with external systems. For organisations looking for solutions that truly add value, agentic RAG is the obvious choice.
This is the vision behind Tilde Enterprise Assistant: an agent-based RAG system built to support complex tasks, adapt to custom workflows and deliver real value.
But great AI doesn’t stop at functionality – it must also understand the language and culture of its users. Once trained, TildeLM will be fine-tuned specifically for RAG, enabling the system to better grasp local grammar, terminology and context – making it not just smart but truly multilingual.