
Mis on lugemisega täiendatud genereerimine (Retrieval-Augmented Generation, RAG)?
Lugemisega täiendatud genereerimisest (RAG) on saanud võimas meetod konkreetsetele valdkondadele kohandatud sisuga suurte keelemudelite (LLM-id) ettevalmistamiseks. Sisuliselt võimaldab RAG-süsteem kasutajatel dokumentide kogumit indekseerida ja küsida loomulikus keeles nende dokumentide sisu kohta küsimusi. Süsteem reageerib, otsides kõigepealt välja dokumendid, mis on päringu suhtes kõige asjakohasemad ning seejärel genereerib LLM selle teabe põhjal vastuse. Lubadus on lihtne: kasutajad saavad küsida omaenda andmete kohta küsimusi, justkui eksperdiga rääkides, ja süsteem annab lühikesi ning kasulikke vastuseid.
Siin on üks näide selle tööst. Kujutage ette, et teil on suur kuhi ettevõtte dokumente ja vaja on üles leida üks aruanne, milles on loetletud teie viis aastat tagasi enimmüüdud tooted. Selle asemel, et kõik ise läbi otsida, on teil nutikas abiline, kes leiab õige aruande, loeb selle läbi ja annab teile sekunditega selge ja täpse vastuse.
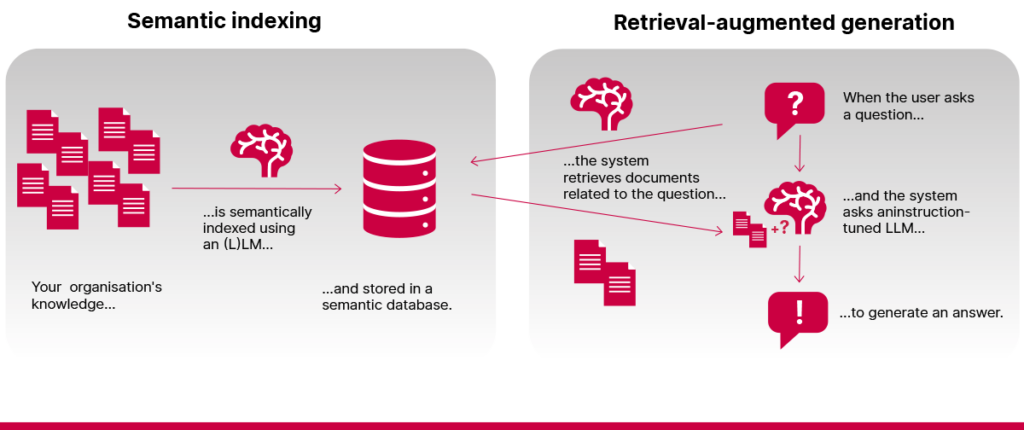
Mida suudab teha lihtne RAG-lahendus?
Lihtne (või naiivne) RAG-süsteem suudab hästi teostada kahte põhifunktsiooni.
1️⃣ Dokumentidest otseste vastuste leidmine. Kui kusagil indekseeritud dokumentides leidub täpne vastus, suudab RAG-süsteem selle leida ja teile edastada. Tihti töötab see paremini, kui traditsiooniline otsing, sest see suudab mõista küsimust isegi juhul, kui see on teie dokumentide sisust teisiti sõnastatud.
2️⃣ Teabest kokkuvõtete tegemine. RAG-mudelid suudavad teha leitud dokumentidest kokkuvõtteid, muutes suured tekstikogumid lühikesteks ja hõlpsamini loetavateks vastusteks.

Millest jääb lihtsal RAG-il puudu?
Vaatamata selle atraktiivsusele, võivad lihtsad RAG-süsteemid kokku puutuda arvukate probleemidega, mille hulka kuuluvad järgmised.
-
- Kehv andmekvaliteet
Andmekvaliteet on sageli peamine jututeema, kui rääkida RAG-i piirangutest ja väljakutsetest – ja seda põhjusega. Kehva kvaliteediga andmed viivad kehva kvaliteediga vastusteni. Kui dokumendid on aegunud, sisaldavad faktivigu, on halvasti struktureeritud või ebatäielikud, siis võib süsteem toota asjakohatuid, eksitavaid või lihtsalt valesid vastuseid. Kuid see on alles jäämäe tipp.
-
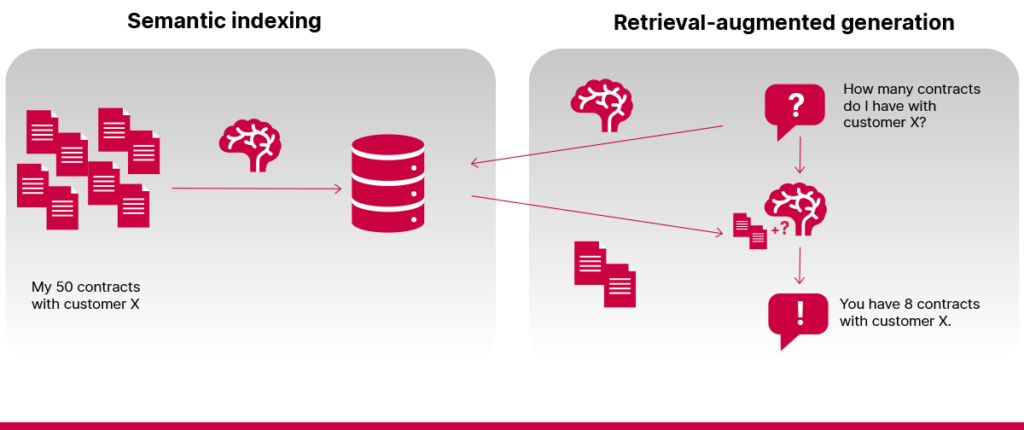
- Vajadus keerukate arutluskäikude või arvutuste järele
RAG-süsteemid ei ole kalkulaatorid ega sidusandmebaasid. Need jäävad hätta ülesannetega, mis nõuavad matemaatikat ja arvutamist. Kui näiteks küsida, mitu lepingut on ettevõttel konkreetse kliendiga, jääb see tihti süsteemi võimalustest väljapoole, kui iga leping on talletatud eraldi dokumendina.
-
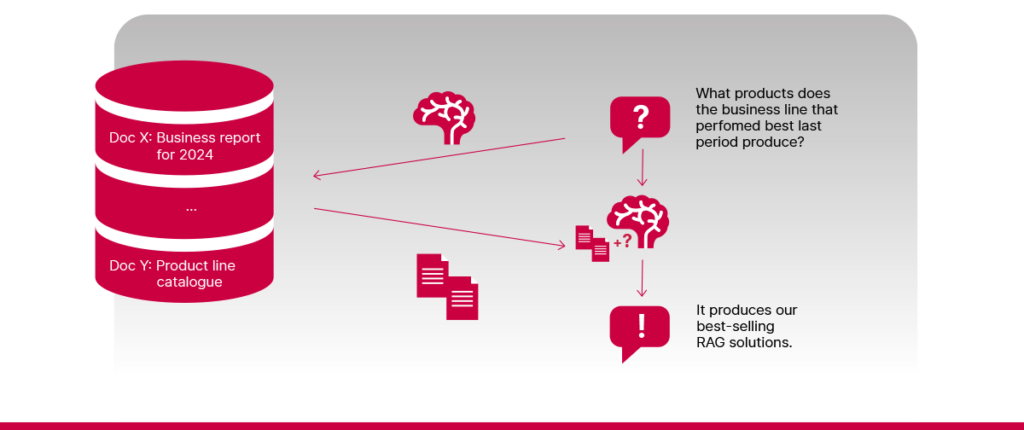
- Vajadus järkjärgulise arutluskäigu järele
Mõned küsimused nõuavad süsteemilt järkjärgulist mõtlemist. Kujutage näiteks ette, et teie teadmistebaas sisaldab kahte dokumenti – ühes on selgitatud, millised olid erinevate ärivaldkondade tulemused eelmisel perioodil, ja teine loetleb, milliseid tooteid kumbki ärivaldkond valmistab. Kui küsite: „Milliseid tooteid valmistab kõige edukam ärivaldkond?“, peab süsteem esmalt välja selgitama, kumb ärivaldkond oli edukam, ning seejärel leidma, mida see valmistab. Sellistel juhtudel ei pruugi lihtsast ühesammulisest otsingust ja vastuse genereerimisest piisata, eriti kui tegeliku elu küsimused on palju keerukamad.
-
- Liitküsimused
Mõnikord võib lihtne küsimus nõuda mitut teabeosa, mis jaotatud mitmesse erinevasse dokumenti. Lihtsal RAG-süsteemil, mis on piiratud vaid ühe ringi või otsinguga, võib ebaõnnestuda kõigi asjakohaste dokumentide samaaegne läbiotsimine ja sellise vastuse genereerimine, mis kataks kõik kasutaja küsimuse aspektid.
-
- Piiratud konteksti pikkus
Kõigil keelemudelitel on maksimaalne sisendi pikkuse piir, mis tähendab, et need tulevad korraga toime vaid teatud pikkuses tekstiga. Kui piir ületatakse, siis ülejäänud kontekst jäetakse välja. Kui näiteks palute teha kokkuvõtte pikast dokumentist või küsite küsimuse, mis nõuab teavet korraga liiga paljudest dokumentidest, võib süsteem jätta kõrvale olulisi üksikasju – lihtsalt seetõttu, et mudel ei „näe“ kõike, mida oleks tarvis täpse vastuse genereerimiseks.
-
- Kasutajaprofiili kontekstipõhine mõistmine
Lihtne RAG-süsteem ei tea midagi kasutaja ega tema rolli kohta. Kui andmebaas sisaldab vastuolulisi dokumente, millest mõned on mõeldud ühele kasutajarühmale ja teised teisele, võib süsteemil tekkida õige konteksti valimisel raskusi, kui puudub kasutajapoolne lisateave. Kujutage näiteks ette, et RAG-süsteemis on indekseeritud kaks dokumenti – üks on mõeldud juriidilistele isikutele, mis sätestab, et äritegevuseks on vaja lepingut, ja teine on mõeldud füüsilistele isikutele, mis sätestab, et lepingut pole tarvis. Kui küsite, kas teil on vaja lepingut, kuid ei täpsusta, kas olete juriidiline või füüsiline isik, võib RAG-süsteem anda teile vale vastuse.

Muidugi on juhuseid, kui RAG-süsteemil õnnestub leida üles kõik asjakohased dokumendid küsimusele, mis nõuab järkjärgulist arutluskäiku. Mõnikord on teave dokumentides esitatud juba kokkuvõtlikul kujul, seega arvutused pole vajalikud. Kuid need on erandid, mitte reegel. Lihtne (naiivne) RAG-seadistus ei ole võimeline käsitlema keerulisi küsimusi või erinevate organisatsioonide konkreetseid vajadusi.
Lihtsast RAG-ist edasiliikumine
Nende piirangute ületamine nõuab täiustatud lähenemist – sellist, mis ulatub kaugemale ühesammulisest semantilisest otsingust ja vastuse genereerimisest. Siin tuleb mängu agendiline lugemisega täiendatud genereerimine.
Agendiline RAG kasutab autonoomseid agente, millest igaüks on mõeldud konkreetset tüüpi ülesannete jaoks, et vastata keerukatele küsimustele. Näiteks, mõned agendid suudavad pikki dokumente kokku võtta, teised teostada arvutusi ja kolmandad otsida ajakohast teavet välistest rakendusliidestest (API-d) jne. Need agendid suudavad täita ülesandeid, millega lihtsad RAG-süsteemid hätta jäävad. Näiteks saab neid kasutada järgmiselt.
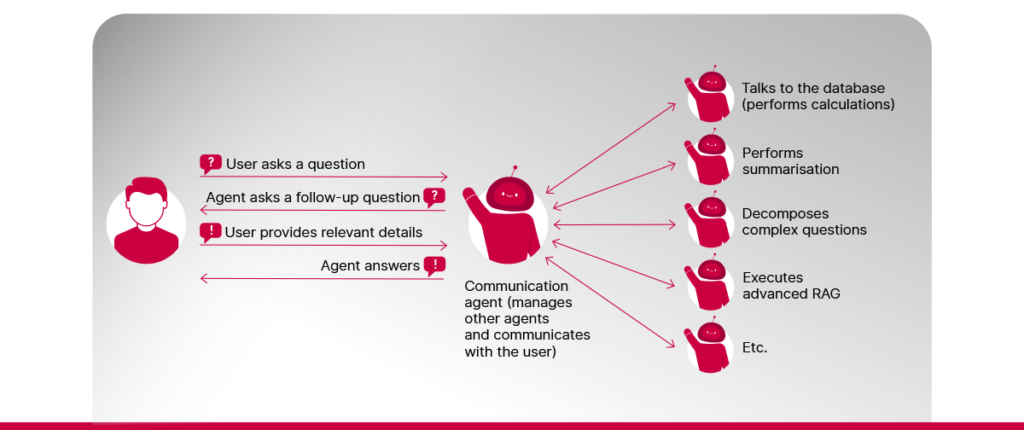
1️⃣ Keerukate küsimuste lahtimõtestamine. Keerukate, mitmeosaliste küsimuste jagamine väiksemateks, arusaadavamateks küsimusteks muudab lihtsamaks asjakohasemate dokumentide otsimise ja liitküsimuste kõiki aspekte katvate vastuste genereerimise.
2️⃣ Kasutajalt teabe kogumine. Kui kasutaja päring on ebaselge või selles puuduvad üksikasjad, saavad agendid sekkuda, et küsida jätkuküsimusi ja koguda kõik vajaliku.
3️⃣ API-de kasutamine. Organisatsiooni dokumentides ei pruugi olla saadaval kogu teavet. Osa andmeid võib olla talletatud sisesüsteemidesse, millele pääseb juurde API-de kaudu. RAG-süsteemi funktsionaalsust on võimalik oluliselt laiendada, lubades sellele juurdepääsu andmetele, mida talletatakse teistes süsteemides.
4️⃣ Andmebaasist teabe otsimine. Kui organisatsioon talletab oma andmeid andmebaasides, saavad LLM-id „tõlkida“ kasutajate küsimused andmebaasipäringuteks. Seejärel saab RAG-agendile anda ülesande neid päringuid täita ja vastuse jaoks teavet koguda. Kui organisatsioonil on sarnase struktuuriga dokumente (nt lepingud, projektide dokumentatsioonid jne), saavad LLM-id aidata ka nendest dokumentidest metaandmete väljavõtmisega. See muudab lihtsamaks andmebaaside loomise juhtudel, kui kasutajad tahavad küsida arvutusi nõudvaid küsimusi.
5️⃣ Küsimustele vastamine täiustatud RAG-i abil. RAG on iseenesest ülesanne, mida saab täita LLM-agent. Lihtsale RAG-ile lisaks tutvustab täiustatud RAG mitmeid meetodeid, mille eesmärk on parandada seda, kui hästi otsib süsteem asjakohaseid dokumente enne vastuse genereerimist, mille hulka kuuluvad järgmised.
-
- Hübriidne semantiline otsing. Üks tõhus meetod on hübriidne otsing, mis ühendab semantilise otsingu traditsioonilise märksõnapõhise otsinguga. See aitab otsida dokumente, mis on asjakohased nii temaatiliselt kui ka leksikaalselt. See on eriti kasulik mitmekesise dokumendikogumi korral.
-
- Hüpoteetiline dokumentide genereerimine. Küsimused erinevad loomult dokumentidest, mida tahame lasta RAG-süsteemil leida. Näiteks on küsimused kokkuvõtlikud ja lühikesed, kuid dokumendid pikad ja üksikasjalikud. Küsimused koosnevad tihti vaid ühest küsimärgiga lõppevast lausest, dokumendid seevastu võivad sisaldada sadu või rohkem lauseid, mis lõpevad vaid harva küsimärgiga. See erinevus on tihti semantilise otsingu ebaõnnestumise põhjuseks. Üks meetod sarnasuse suurendamiseks on esmalt tekitada kasutaja küsimusele hüpoteetiline dokument (või vastus) ilma mingisugust konteksti kasutamata. Seejärel kasutab süsteem genereeritud teksti, et otsida andmebaasist sarnaseid dokumente, mis viib tihti paremate tulemusteni.
-
- Dokumentide jaoks küsimuste ja teeside genereerimine. See on veel üks meetod, mille abil küsimuste ja dokumentide vahel semantilist lõhet vähendada. Kui kasutajad laadivad üles dokumente, saame paluda LLM-il genereerida potentsiaalseid küsimusi või kokkuvõtlikke faktiliste väidete (teeside) loendi iga üleslaaditud dokumendi kohta. Me indekseerime need küsimused ja teesid semantilises andmebaasis koos originaaldokumendi lingiga. Kui kasutaja küsib küsimuse, võrdleb süsteem seda nende lühemate, küsimustelaadsete kirjetega, muutes kõige asjakohasemate dokumentide leidmise lihtsamaks.
-
- Leitud dokumentide ümberjärjestamine. Kõik leitud dokumendid ei ole ühtselt kasulikud või kasutaja küsimuse jaoks asjakohased. Need võivad sarnaneda kontekstipõhiselt, kuid ei taga asjakohasust. Selle parandamiseks saab ümberjärjestav LLM leitud dokumendid üle vaadata, nende asjakohasust hinnata ja need sobivalt järjestada. See aitab tagada, et generatiivne LLM kasutab vastuse moodustamisel kõige asjakohasemat konteksti.
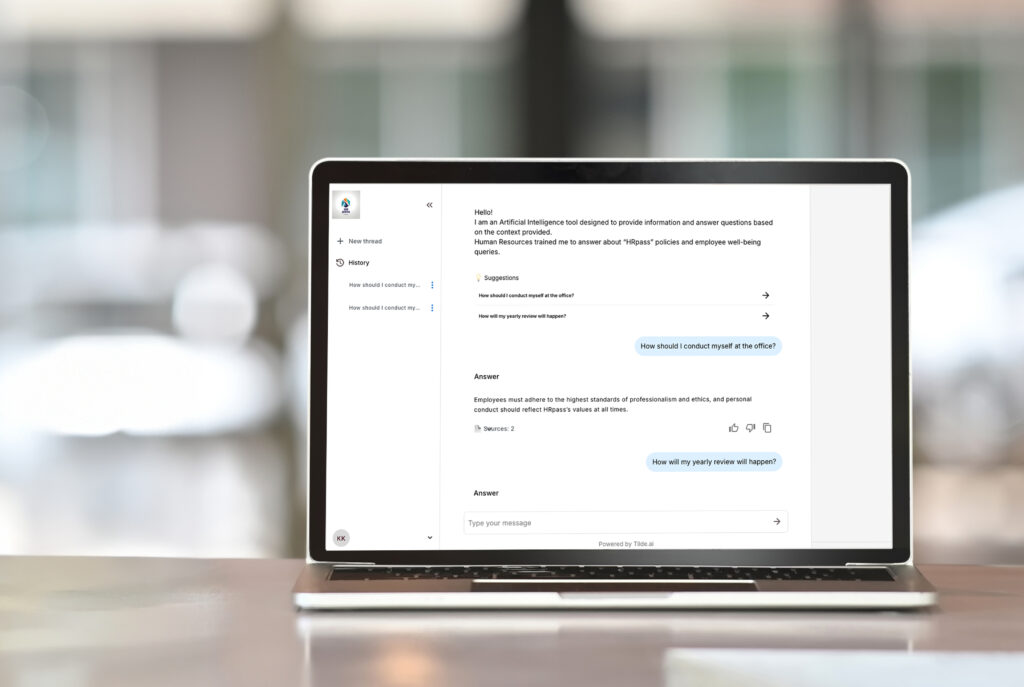
Tilde Enterprise Assistant on võimekas näide agendilisest RAG-lahendusest, mis on loodud kohanema organisatsiooni konkreetsete vajadustega. Põhifunktsioonide hulka kuuluvad järgmised.
-
- Hübriidne semantiline otsing koos integreeritud andmete genereerimisega, kasutades LLM-e.
-
- Liitküsimuste lahtimõtestamine täpsemate ja täielike vastuste andmiseks.
-
- Automatiseeritud metaandmete eraldamine dokumentidest ja andmebaaside kogumitest.
-
- Dialoogipõhised stsenaariumid väliste API-de kasutamiseks või otse kasutajatelt teabe kogumiseks.
-
- Paindlik mudelivalik, mis võimaldab hõlpsasti vahetada indekseerivate LM-ide ja generatiivsete LLM-ide vahel.
-
- Hästi kohandatavad töövood, mis on kohandatud erinevatele ettevõtete kasutusviisidele.
Keelemudelite roll RAG-is
Üldiselt kasutavad RAG-süsteemid kolme erinevat tüüpi keelemudeleid: indekseeritud (või integreeritud) keelemudel, ümberjärjestav keelemudel ja generatiivne LLM. Praeguse tehnika uusima tasemega avatud ja suletud LLM-id on valdavalt inglise keele kesksed, andes vähem täpseid vastuseid keeltes, mis on treeningandmetes väiksema esindatusega. Väiksemad keeled, nagu läti, leedu ja eesti keel, saavad tihti vähem tähelepanu, ja seetõttu võib LLM-ide vastustes tekkida ebagrammatilisi väljundeid, kultuurilisi väärtõlgendusi või kohalike teadmiste puudumist.
Selleks, et olemasolevate suurte keelemudelite lingvistilisi ja kultuurilisi puudujääke kõrvaldada, on Tilde arendamas TildeLM – avatud fundamentaalne LLM, mis on kohandatud Euroopa keeltele. Meie fookuskeeled on balti, läänemeresoome ja slaavi keeled. Eesmärk on, et kõik meie fookuskeeled oleksid võrdselt esindatud, tagamaks, et mudel õpib kohalikke eripärasid, grammatikat ja kultuurilisi nüansse – seda, mis on inglise keele kesksetel mudelitel tihti puudu. TildeLM-i treenimine algas 2024. aastal LUMI superarvutil Soomes. Kui see saab valmis, häälestatakse mudelit ülesannete jaoks, nagu masintõlge, konteksti raames küsimustele vastamine (nagu kasutatakse RAG-süsteemides) ja palju muud.
Kokkuvõte
Kuigi lihtsad RAG-süsteemid tulevad toime otseste päringutega, ei suuda need sageli toime tulla tegeliku elu keerukusega – mitmesammuline arutluskäik, mitmetähenduslikud küsimused või ülesanded, mis nõuavad suhtlemist väliste süsteemidega. Organisatsioonide jaoks, kes otsivad tõelisi lisaväärtuseid pakkuvaid lahendusi, on agendiline RAG ilmselge valik.
See on Tilde Enterprise Assistanti eesmärk: agendipõhine RAG-süsteem, mis on loodud toetama keerukaid ülesandeid, kohanduma kohandatud töövoogudega ja lisama tõelist väärtust.
Kuid suurepärane tehisaru ei peatu funktsionaalsuse juures – see peab mõistma ka oma kasutajate keelt ja kultuuri. Kui treenimine on lõpule viidud, häälestatakse TildeLM spetsiaalselt RAG-i jaoks, võimaldades süsteemil paremini mõista kohalikku grammatikat, terminoloogiat ja konteksti, muutes selle mitte ainult nutikaks, vaid ka tõeliselt mitmekeelseks.



