
Daktaras Toms Bergmanis, AI Tyrinėtojas Tilde
Norint kurti DI sistemas, galinčias suprasti ir generuoti žmonių kalbą, reikia labai daug kalbos duomenų. Šie duomenys tampa pagrindu didelių kalbos modelių (large language model – LLM) gebėjimui suprasti ir kurti kalbą, panašią į žmogaus. Vis dėlto klišė byloja, kad ne visi duomenys yra vienodai geri, o tai ir gali įtakoti modelio veikimo kokybę.
Kaip rodo naujausių Europoje ir Amerikoje sukurtų LLM kortelės/aprašai, modelių mokymui naudojama labai daug teksto. Vis dėlto tik dalis šių duomenų yra aukštos kokybės ir kruopščiai atrinkti. Didžioji dalis gaunama oportunistiškai, tiesiog automatiškai grandant duomenis iš interneto.
„Tilde“ įmonėje kurdami pamatinį daugiakalbį LLM „TildeLM“susiduriame su praktine problema, kurią atspindi gerai žinomas posakis „ką pasėsi, tą ir pjausi“. Viena vertus, mūsų skaičiavimai rodo, kad norint išmokyti 30 mlrd. parametrų pamatinį LLM, reikalingas maždaug 600–700 mlrd. žodžių duomenų rinkinys. Kita vertus, pradėjus detaliau analizuoti turimų duomenų kokybę, tai, kas iš pirmo žvilgsnio atrodo kaip lobynas, vis dažniau primena Pandoros skrynią.
Dabartinių duomenų rinkinių trūkumai
Daugiausia turimų duomenų, skirtų mokyti LLM, gaunama iš dviejų pagrindinių šaltinių: „Common Crawl“ ir „Internet Archive“– dviejų saugyklų, sukurtų automatiškai grandant duomenis iš milijonų tinklalapių. Nors iš šių šaltinių ir surenkama daug medžiagos, jie turi ir reikšmingų trūkumų, ypač jei tekstai ne anglų kalba.
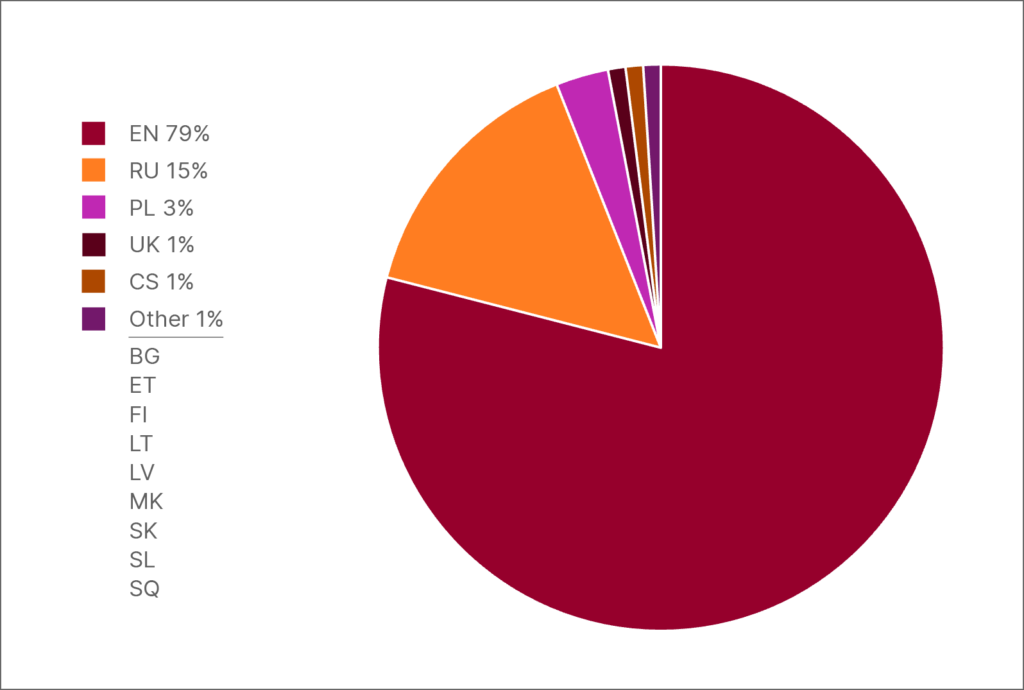
Duomenų pasiskirstymas HPLT-v2: anglų k. ir 13 kalbų, kuriomis kalba daugiau nei 250 mln. žmonių
Nepriklausomai nuo pasirinkto duomenų rinkinio, anglų kalba dominuoja. Anglų kalbos žodžių skaičius visuose duomenų rinkiniuose ne tik lenkia bet kurią kitą kalbą, bet ir viršija ištisiems regionams priklausančių kalbų duomenų apimtis.Tai pagrindinė priežastis, kodėl daugiau nei 90 % LLM mokymo duomenų sudaro tekstai anglų kalba, o daugelis kitų kalbų lieka nepakankamai atstovaujamos. Toks disbalansas lemia „anglocentrizmą“, kai dirbtinio intelekto modeliai puikiai moka anglų kalbą, bet sunkiai susidoroja su kitų kalbų niuansais ir kultūriniais ypatumais. Nepakankamai atstovaujamų kalbų vartotojams tai reiškia prastesnės kokybės dirbtinio intelekto priemones ir ribotas galimybes naudotis pažangiomis technologijomis.
Pastebime, jog nemažą dalį neangliško teksto sudaro žemos kokybės mašininiu būdu išverstas turinys. Pavyzdžiui, išanalizavę 300 dažniausiai pasitaikančių HPLT-v2 latvių kalbos duomenų rinkinio aukščiausio lygio interneto domenų, nustatėme, kad net 25 % jų sudaro mašininiu būdu išversti tinklalapiai..
Ši problema atsiranda ne tik dėl prastos vertimų kokybės, bet ir todėl, kad vertimai apskritai retai kada laikomi tinkamu kalbos atspindžiu, nes pernelyg tiksliai atkartoja originalo kalbos struktūrą. Šis reiškinys vadinamas translationese ir lemia nenatūralias frazes, gramatines klaidas ir kultūrinio konteksto praradimą. Todėl tokiais duomenimis apmokyti dirbtinio intelekto modeliai gali neefektyviai suprasti ar generuoti niuansuotą turinį šiomis kalbomis.
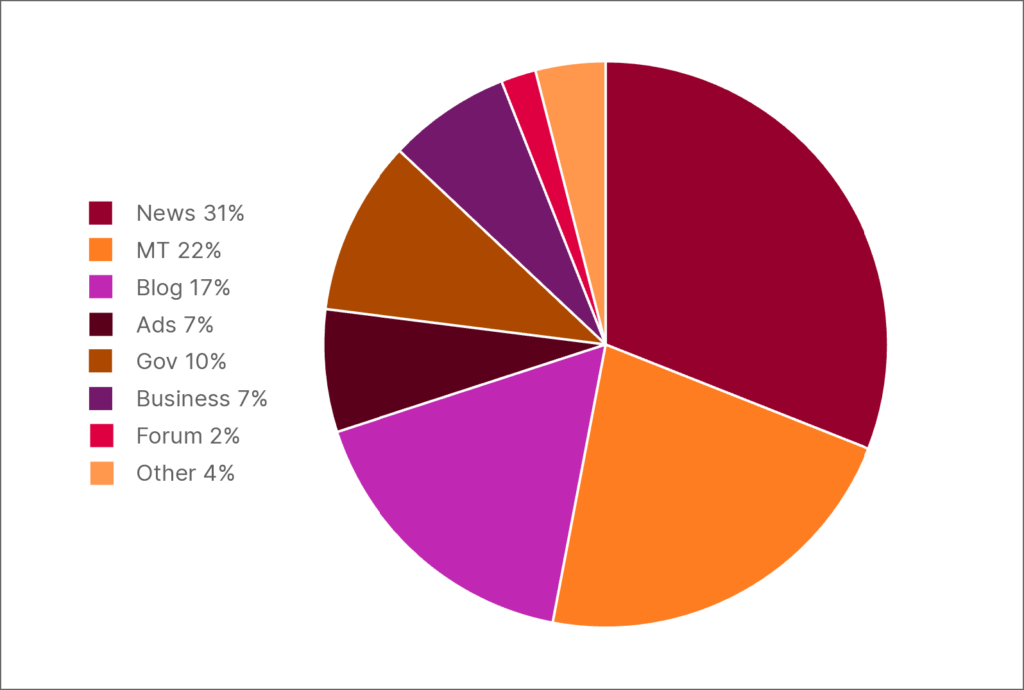
Domeno žymų pasiskirstymas tarp 300 dažniausių aukščiausio lygio interneto domenų HPLT-v2 latvių kalbos duomenų dalyje
Šališkumo ir dezinformacijos keliami iššūkiai
Be problemų, susijusių su tokiomis ypatybėmis kaip netaisyklinga gramatika ar kalbos normų nesilaikymas, yra ir rimtesnių. Nagrinėdami duomenis iš, regis, patikimų šaltinių, radome turinio, kuris buvo netinkamas arba nesusijęs su mūsų mokymo tikslais. Dažnai turėjome spręsti, koks turinys yra priimtinas, koks ne. Lengva atpažinti tokią medžiagą kaip pornografija ir pagrįsti jos neįtraukimą: pornografija tiesiog reikšmingai neprisideda prie kalbos supratimo.Tačiau kitą turinį nustatyti daug sunkiau, o modeliai, apmokyti naudojant tokį turinį, gali kelti etikos ir saugumo problemų.
Verta paminėti politinį turinį, ypač iš prorusiškų žiniasklaidos šaltinių. Šis turinys dažnai skleidžiami stiprūs antivakarietiški ir prieš LGBT nukreipti naratyvai, prorusiškos nuotaikos ir antiukrainietiška propaganda. Daugelis tokių svetainių ES uždraustos dėl tokių organizacijų, kaip Latvijos Nacionalinė elektroninės masinės žiniasklaidos taryba, kuri taip pat paskelbė uždraustų svetainių sąrašą ir taip palengvino jų atskirtį, pastangų. Daug Prorusiška Serbijos žiniasklaida kelia dar didesnį iššūkį.Nors ji nėra uždrausta ES, daugelis svetainių skelbė gandus arba „ekspertų nuomones“ lydimas suklastotų nuotraukų, siekdamos skleisti Kremliaus pasakojimus apie Vakarų karinę agresiją.

Serbijos prorusiškos žiniasklaidos svetainė, kurioje naudojami suklastoti vaizdai netikroms naujienoms skleisti. Antraštė: „NATO kariniai konvojai užtvindė Lenkijos kelius: Lebedevas atskleidžia šokiruojančius planus!“
Tokia medžiaga kelia problemų ne tik dėl politinio šališkumo, bet ir dėl to, kad joje melaginga informacija tokiose srityse kaip istorija, medicina ir socialiniai klausimai pateikiama kaip faktai, taip siekiant skleisti nesantaiką tarp europiečių. Kai LLM mokomi naudojant tokius duomenis, rizikuojama sustiprinti žalingus stereotipus ir dezinformaciją, o tai gali pakenkti modelio objektyvumui ir naudingumui realiose taikymo srityse.
Kokybiškų duomenų poreikis
Akivaizdu, kad norint sukurti veiksmingą LLM reikia ne tik didžiulių tekstų kiekių, bet ir aukštos kokybės, įvairių ir patikimų duomenų rinkinių. Norint mokyti LLM,reikia duomenų kurie pastūmėtų modelius mokytis kultūrinio konteksto ir sudėtingų samprotavimų.Kaip rodo ankstesni pavyzdžiai, naivu pasikliauti vien tik dideliais žiniatinklio duomenų kiekiais.
Deja, daugelis aukštos kokybės duomenų rinkinių kitomis nei anglų kalbomis yra maži arba fragmentuoti.
LLM mokymas reikalauja ilgų teksto ištraukų, kurios leistų suvokti pasakojimo eigą ir kontekstą. Be jų LLM kalbos „supratimas“ išlieka paviršutiniškas. Net ir gerai parašytos, tačiau trumpos ištraukos nėra pakankamai išsamios, kad būtų galima modelį gerai ištobulinti.
Licencijavimo apribojimai dar labiau apsunkina šią problemą.
Daugelio akademinių projektų, finansuojamų nacionalinių vyriausybių, rezultatas – iš pavienių sakinių sudaryti duomenų rinkiniai, kurie netinkami LLM mokymui. Be to, dauguma tokių išteklių yra skirti tik akademiniams tyrimams ir yra neprieinami komerciniam naudojimui, todėl komerciniams tyrėjams tenka pasikliauti oportunistiškai surinktais duomenimis.
Prastos kokybės duomenų naudojimas daro įtaką ne tik LLM veikimui, bet ir mums bei pačioms kalboms. Kai dirbtinio intelekto sugeneruotas turinys tampa vis dažnesnis (naudojamas el. laiškuose, straipsniuose ir rinkodaros medžiagoje), keičiasi kalbos vartojimas ir suvokimas. Atsižvelgiant į tai, jog šie įrankiai gerai perpranta ir atkartoja kalbinius ypatumus, plačiai naudojant DI sugeneruotą tekstą ilgainiui normalizuojamos klaidos ar nenatūralūs modeliai, o tai gali pakenkti kalbos turtingumui.
Europos bendradarbiavimas siekiant geresnio dirbtinio intelekto
Nepaisant visų iššūkių, randasi padrąsinančių bendradarbiavimo su duomenų donorais, kurie teikia aukštos kokybės duomenų rinkinius, pavyzdžių. Pirmasis mūsų partneris – Estijos kalbos institutas (EKI) – ėmėsi aktyvių veiksmų, siekdamas užtikrinti, jog estų kalba būtų gerai atstovaujama mokant dirbtinį intelektą. EKI pasiūlė savo išteklius bei suteikė įvairios medžiagos, tokios kaip literatūros kūriniai, vyriausybiniai leidiniai. Šie duomenų rinkiniai yra neįkainojami mokant modelius suprasti tiek formalų, tiek neformalų kalbos vartojimą, taip užtikrinant, kad kuriami įrankiai tiksliau ir jautriau atlieptų bendruomenės poreikius bei kultūrinius ypatumus.
Lenkijoje veikianti visuomeninė organizacija „SpeakLeash“ taip pat daug nuveikė siekdama išsaugoti lenkų kalbą. „SpeakLeash“, kuriai vadovauja savanoriai, kuria ir kataloguoja duomenų rinkinius, specialiai pritaikytus kalbai dirbtinio intelekto įrankiuose palaikyti.
Abi organizacijos įnešė vertingą indėlį į „TildeLM“, padėdamos užtikrinti, kad Baltijos ir Rytų Europos kalbos būtų taip pat išsamiai ir įvairiapusiškai atstovaujamos. EKI ir „SpeakLeash“ nėra vienintelės organizacijos, kurios mums padeda. Taip pat Suomijos nacionalinė biblioteka, Ľ. Štúr kalbotyros institutas Slovakijos mokslų akademijoje, Slovėnijos kalbos modelio iniciatyva, Zagrebo universiteto Humanitarinių ir socialinių mokslų fakultetas ir Univerzita Komenského v Bratislave.
Tokios iniciatyvos rodo, kaip vietos bendruomenės ir organizacijos gali aktyviai užtikrinti, kad jų kalbinis paveldas būtų išsaugotas skaitmenine forma.
Kas laukia ateityje
Iššūkiai, su kuriais susidūrėme kurdami „TildeLM“ – nuo paprastų kokybės problemų iki šiuolaikinio netikrų naujienų ir propagandos „maro“ – atskleidžia, kad „daugiau yra geriau“ yra iš esmės klaidingas. Patikrinti trilijonus žodžių dideliuose duomenų rinkiniuose yra praktiškai neįmanoma, be to šis iššūkis kasdien tampa vis sudėtingesnis. Akivaizdu, kad tolesnis LLM kelias nėra vis didesnių duomenų kiekių kaupimas, be to prognozuojama, jog turimi aukštos kokybės duomenys artimiausiais metais išseks.
Tik laikas parodys, ar dirbtinio intelekto ateitis priklausys nuo apgalvoto technologijų įmonių, akademinių institucijų ir kultūros organizacijų bendradarbiavimo. Partnerystė su tokiomis organizacijomis kaip Estijos kalbos institutas ir „SpeakLeash“ rodo, kad toks bendradarbiavimas yra įmanomas. Dabar svarbu išsiaiškinti, ar toks sėkmingo bendradarbiavimo modelis gali būti išplėtotas už atskirų sėkmės istorijų ribų ir tapti pagrindu geresnės kokybės modeliams, apmokytiems naudojant mažesnius, bet patikimesnius duomenų rinkinius. Atsakymas į šį klausimą gali nulemti, ar dirbtinis intelektas sugebės vienodai gerai pasitarnauti visoms kalboms ir kultūroms.



